
Web Data Extract Summit 2024 Recap
The 2024 Web Data Extract Summit celebrated both its debut in Austin, USA and its sixth year since launching in 2019.
The two-day event began with a day of hands-on technical workshops, followed by an action-packed second day of curated sessions:
Four talks explored AI-related applications of web data,
Two talks addressed business strategies for leveraging web data,
Three sessions focused on the infrastructure driving web scraping operations, and
Two sessions delved into legal, ethical, and compliance considerations.
Before we move on, let’s acknowledge that you may be exhausted from reading and hearing about AI at this point. However, its potential to impact your bottom line is difficult to ignore especially if you’re leveraging web data extraction in any capacity.
What are others doing with their data extraction practices? What opportunities could you be missing? And most importantly, what should you be doing differently to stay ahead?
We hear you—and we get the AI fatigue. That’s why our team at Zyte made sure that we cover all the bases, from technical, business, and legal aspects of web scraping when we curated this year’s Extract Summit lineup of 11 talks.
Each technical talk offered unique perspectives and complemented the others well. However we noticed a couple of recurring themes. Keep reading to find out what those are.
To provide a clear overview, we've divided this recap into two main sections: one focusing on technical insights and the other on business implications.
Technical Insights for Developers Doing Web Data Extraction
Here are the five recurring topics across the technical talks:
Infrastructure as a service: We now have increasingly-intelligent and distributed computational infrastructure, all available on-demand. There are three talks on this topic from proxies, browsers, and distributed compute.
Tapping into AI: We get a view of how AI changes the economics of build vs buy at Zyte and how Neelabh Pant’s team at Walmart uses AI agents to streamline their data pipeline orchestration.
Managing LLM costs: At this moment, LLMs + HTML = pricey. How to best manage this? How does this change with multimodal models? These are some of the motivating questions that Iván Sánchez from Zyte and Asim Shrestha from Reworkd unpacked in their talks.
The importance of domain-specificity when approaching prompt engineering and writing evals. To unlock the potential of LLMs for your data, you still need people with domain knowledge. Here we hear Neelabh share the one technique that landed his team at a sweet spot by designing domain-specific prompts and leveraging AI agents. And then we have Asim from Reworkd highlighting the importance of writing domain-specific evals to simplify the problem space.
Retrieval-augmented generation (RAG): Neelabh highlighted how RAG helped his team in identifying top similar products, stressing the need for careful experimentation with the number of items retrieved to maintain contextual accuracy and relevance. Jan from Apify then positioned RAG as a game-changer for commercial LLM applications. He demonstrated a website content crawler that is integrated with RAG pipelines and a vector database backend, Pinecone.
Ready to zoom in? Let’s—but not without a map.
If we think of the web data extraction stack as a layered structure, then we can map the different sessions onto its key components. Here’s a visual breakdown of how these sessions align:
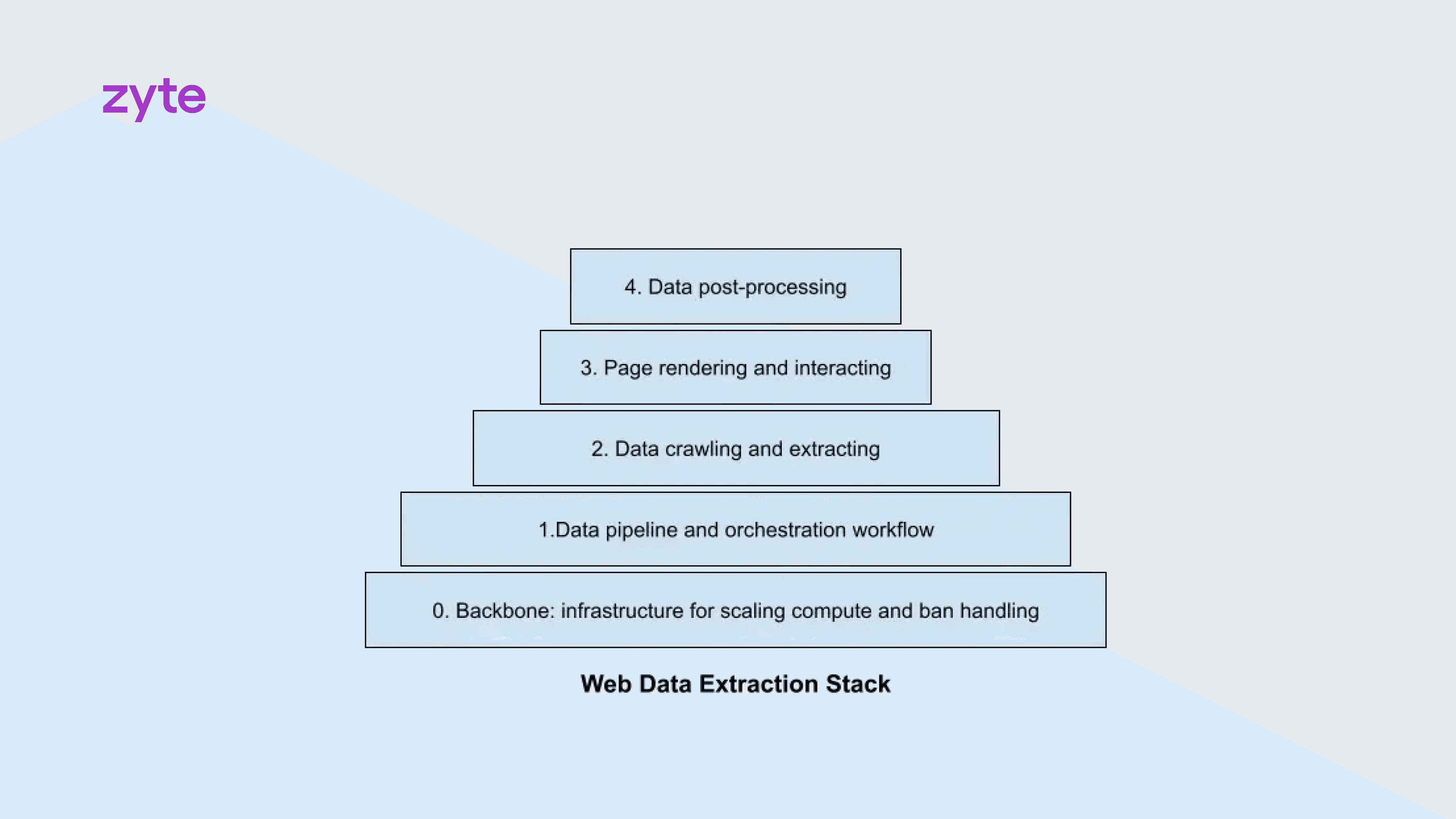
You can also watch the respective sessions for each topic on demand here.
Infrastructure for ban handling > Proxy management
• Trends and challenges in proxy usage
• How IP reliability are managed and how fraud scoring work
• How geolocation databases are used to conduct geolocation and IP management
• Implications that unethical proxy service providers have on the market and what you need to be aware of as a user of these services
Infrastructure for ban handling > Proxy management
• Three techniques for managing browser automation (cache, cookies, and process management)
• A poor man’s way to scale using Chrome
• Good use cases for using a cache in web applications
• The advantages of using cookies compared to user data directories
• Considerations should be made when choosing a caching strategy
• What tool Joel used for load balancing and route requests
Infrastructure for ban handling > Proxy management
• Some of the unique features of Charity Engine’s large-scale distributed computing resources
• Flexible development options that developers get access to
• How Docker and WebAssembly files play into this.
• Who can donate compute and who can purchase the compute
• How Charity Engine ensures data privacy and security when using volunteered computing resources
• What systems and processes are put in place to detect and prevent misuse such as DoS attacks
Data pipeline and workflow
• The limitations of traditional data processing methods
• How Neelabh’s team use LLMs to address common issues found in data engineering for retail datasets such as missing categories and descriptions
• How category-specific prompts are constructed for feature extraction
• The ethical considerations when using LLMs to generate or impute missing data, especially in sensitive industries
Data crawling and extraction
• Why we want to consider using LLMs for data extraction when traditional scraping methods exist
• How Ivan optimized for token usage and how it affects cost and performance
• What the ROUGE metric is
• Findings regarding fine-tuning versus in-context learning for LLMs
• Why quality data trumps noisy data in quantity for LLMs training
• The current limitations of running LLMs at scale
• How Ivan mitigated the hallucination problem in LLM-based web data extraction
Rendering and interacting
• The limitation of using raw HTML for webpage parsing
• The importance of visual cues in web pages and the limitations of HTML alone
• Reworkd’s implementation of 2D rendering algorithm that leverages OCR to transform web pages into structured strings (and it’s open source!)
• The importance of evals for iterating and improving on web tasks and why Reworkd AI developed and released Bananalyzer to tackle this issue
Data processing
• The Value of Retrieval-Augmented Generation (RAG) for LLM Applications
• The process of building a customer support agent with LLMs and RAG
• How to use Apify’s website content crawler and Pinecone integration to scrape data and store it in a vector database for use in RAG pipelines
• Why it is important to strip down HTML content when scraping
Beyond the technically focused talks, one session proved equally significant for developers as well as business leaders: A Practical Demonstration of How to Responsibly Use Big Data to Train LLMs by Joachim Masar.
Joachim offered three key actionable recommendations valuable for anyone involved in implementing a web data extraction stack.
AI-Assisted Data Cleaning: Use LLMs to assist in cleaning data by identifying and removing sensitive information like names and phone numbers.
Privacy, Anonymisation, and Bias Mitigation: Prioritize filtering out Personally Identifiable Information (PII) during the data collection stage. This involves more than just removing usernames but also thorough examination of the content to ensure no sensitive information is inadvertently included. Be aware of potential biases in scraped data, such as demographic overrepresentation. Techniques like word clouds can help identify biases.
Data Security and Privacy Practices: Use techniques like differential privacy and human-in-the-loop systems to improve data handling processes.
He also delved into the challenges of using publicly scraped data, particularly the risk of a model memorising specific data points, which could compromise privacy and violate ethical guidelines. He highlighted key considerations for deploying models in low-resource contexts, where constraints like limited computational power and sparse training data demand creative and efficient solutions.
These thought-provoking questions were also addressed during the talk:
Should companies behind LLMs make their models open source to foster transparency and community collaboration?
Can niche models be improved by retrofitting context using datasets with similar themes, thereby enhancing their applicability to specialised tasks?
How can overfitting be mitigated when incorporating human-in-the-loop feedback, ensuring the model remains generalisable while benefiting from nuanced corrections?
Business Insights For Business Leaders Buying Web Data
If you're a business leader working with web data, these sessions are a must.
John Fraser | Founder at Parts ASAP
• The challenges of in-house web data extraction
• What factors John considers important when looking for a partner for web scraping
• Why PartsASAP employs human verification in the process of matching product details
• What a streamlined process adopting a standardised schema allowed PartsASAP to do
• What contributed to PartsASAP’s 20% YoY growth
• Why John advocated for a “collect now, analyse later” approach
• What John means by “consistency over reactivity”
Iain Lennon | Chief Product Officer at Zyte
• How the cost of data extraction changed over time.
• The different cost structure of generative AI and custom code in handling less structured, “wicked” problems
• The tradeoff between freedom and schema in AI
• How to control the costs associated with using large language models
• The overarching problem that Zyte aims to solve with composite AI
• What impact high setup costs of data products has on customers
Jason Grad (Massive), Neil Emeigh (Rayobyte), Ovidiu Dragusin (Servers Factory), Shane Evans (Zyte), Tal Klinger (The Social Proxy), and Vlad Harmanescu (Pubconcierge)
• Impact and implications of unethical proxy services to the customers and the industry.
• Methods used by ethical IP companies to source, monitor, and ensure compliance.
• Trends and challenges in proxy usage, e.g. success rates of data center IPs, residential, and ISP proxies.
• The complexities of managing IP geolocation.
Matthew Blumberg | Co-founder at Charity Engine
• Ideas of how web scraping and infrastructure can be used for good. From genomic sequence screening, to drug candidate identification
• Details of Charity Engine’s socially conscious business model
• How Charity Engine ensures data privacy and security when using volunteered computing resources
• Market potential of distributed computing services in AI
Joachim Asare | AI/ML Engineer & Master’s in Design Engineering at Harvard University
• What you should consider when deploying a model in a low-resource context
• Why data buyers should demand transparency and ethical data handling from their providers
• The implications of using pre-trained models for businesses and how AI models may require additional fine-tuning and security checks to meet specific use case requirements
• How success from using synthetic data to train models varies by use case
Sanaea Daruwalla (Zyte), Hope Skibitsky (Quinn Emanuel), Stacey Brandenburg (ZwillGen), and Don D'Amico, (Glacier Network and Neudata)
• The legality of web scraping operations and the nuances of what, how, and why data is being scraped
• How multiple types of statutes and legal theories play into the legal landscape of web scraping
• The distinction between browse wrap and click wrap terms of service and their enforceability
• The panelists’ perspective on the X vs. Bright Data case, focusing on allegations about the impact of scraping on target servers
• Discussions on the rising number of legal cases in the AI world, and the significance of the “monkey photo” case in the AI copyright discussions
This session was highly informative and well worth blocking out one hour to digest the nuanced discussion.
Closing Thoughts
Hope this snapshot piqued your curiosity and gave you a good foundation to start surfacing the rich insights from each talk. You can find the full playlist of the day-two sessions here.
You can also watch the on-demand talks from the past six years of Extract Summit here to gain a deeper perspective of how the landscape has evolved throughout the years.
If you didn’t manage to attend in 2024, here is your chance to register for the 2025 event. Do consider applying for a speaking slot!