
Buy or Build? The Four Roads to Acquiring Web Data
Picture this: Your company is scaling fast, and data is at the heart of your operations.
You need a reliable way to collect it – but should you build an in-house solution or buy one?
The decision comes down to control, technical expertise, and how quickly you need the data to start delivering value.
🎥 Watch: An in-depth look at the “Build vs. Buy” dilemma in web data acquisition.
Let’s explore four paths you might choose.
1. The Data Foundry: DIY approach
Imagine you decide to build everything yourself. You gather a team of engineers, design your own crawlers, set up your own servers, chart on the learning curve, and make every decision. This path gives you total control.
But it comes at a cost. Your team works long hours on the setup, and the system needs constant care. Every time a target website changes its layout or blocks your crawler, your team must jump in and try to fix the problem.
This option is like building your own house from the ground up—it can be exactly what you want, but it takes time, money, and constant effort.
Pros:
Maximum control and full customization.
Tailored security, compliance, and quality measures.
Cons:
High initial development costs and longer time to market.
Requires a dedicated team for continuous maintenance and troubleshooting.
Scalability challenges are handled entirely by your internal resources, making it difficult to adapt quickly if target sites update their structures or impose bans.
Ideal for:
Organizations with deep technical resources and a strategic need for complete control.
Projects where data acquisition is a core competitive advantage.
2. The Franken-Stack: Mixed-vendor approach
Now, picture another scenario. Instead of building every part yourself, you mix and match services.
Like assembling a kit car from parts bought from different stores, you build your data acquisition pipeline by piecing together a custom solution from various APIs and services offered by specialist providers. You may call on some or all of the four common types of APIs that help you access web data at scale – parsing or crawling, proxy access, browser infrastructure and unblocking
This option offers more flexibility than building from scratch, but it can be troublesome to manage. Sometimes the pieces don’t work perfectly together because each vendor’s tool can adhere to different standards and update cycles that you need to reconcile on your own. If one vendor updates or discontinues its service, it can break your pipeline, forcing you to rework your integrations or find alternatives.
Pros:
Allows you to mix best-of-breed solutions for specific tasks.
Reduces the burden of developing every component from scratch.
Provides some flexibility in customizing, optimizing, and controlling each element of the pipeline.
Cons:
Integration can be complex, as you must manage compatibility and communication between multiple vendors. Higher overhead in terms of setup and maintenance.
Maintenance becomes a patchwork effort, and any change in one component can ripple through your system.
Ideal for:
Companies with moderate technical resources, in trial-and-error mode, looking for tailored performance without a complete in-house build.
Projects where customization is important, yet speed-to-market is also a factor.
3. The Swiss Army Knife: Full-stack Web Scraping API
Imagine a third path: using a full-stack Web Scraping API.
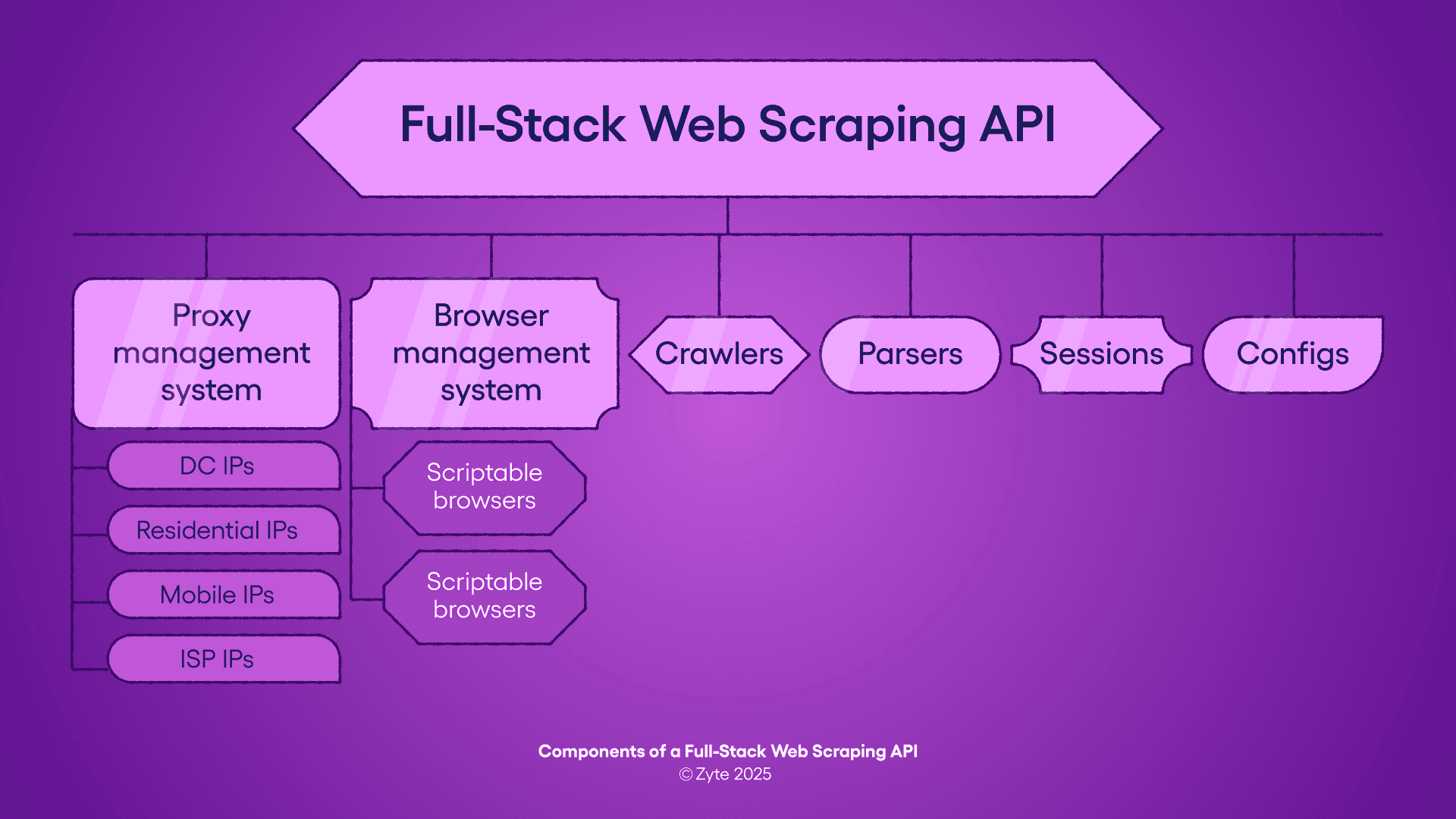
This emerging web data extraction tooling category combines everything you might need—crawling, extraction, proxy rotation, and more—in a single API endpoint. It’s like buying a well-built car that comes with customizable features.
Zyte API is an example of this all-in-one solution. With Zyte API, you set up quickly and have the technical complexities and costing work baked into the single API endpoint. This option saves you time and effort while giving you a good amount of control over the data you collect.
Pros:
Reduces setup time and operational complexity. Frees your internal teams to focus on core business logic rather than on maintaining technical infrastructure.
Offers robust, integrated capabilities built to handle popular sites and anti-scraping measures.
Improved visibility into the total cost of ownership through a single pricing model that eliminates the need to manage multiple services or contracts.
Cons:
Not configurable beyond what the provider supports.
Reliance on a single vendor for all functionalities.
Ideal for:
Organizations seeking a balance between control and outsourcing to a trusted provider without the full burden of building from scratch.
4. The Data Caretaker: Fully managed data service
Finally, consider the option where everything is handled for you. In a fully managed data service, experts do the entire web data acquisition process on your behalf, from end to end.
They handle the setup, infrastructure, maintenance, and compliance, ensuring your data pipeline runs smoothly without your team having to manage technical hurdles. You gain a technical partnership where web data experts ensure that the data flows smoothly and scales as your needs grow.
Zyte Data offers this approach with zero setup costs for common data types supported by its AI scraping solution. Whether you need standard data extraction or bespoke projects, you gain a technical partnership with web data experts who manage everything—from navigating anti-bot measures to built-in legal compliance with the help of Zyte’s world-class legal team.
Pros:
Eliminates the need for internal technical resources dedicated to data collection.
Provides a turnkey solution with robust support, maintenance, and compliance handled by experts.
Offers predictable, subscription-based pricing with minimal operational overhead.
Cons:
Initial setup requires collaboration to define scope, formats, and refresh cycles to match your needs.
Reduced customization and control compared to building in-house.
Ideal for:
Businesses that see data acquisition as a commodity or a chore and want their technical resources to stay focused on their core business activities.
Data projects with proven ROI that require high scalability and reliability without diverting internal talent.
Mapping the four paths
To make these four paths easier to compare, the following diagram allows us to think about two considerations, each of which has a sliding scale:
Operational involvement: How much hands-on effort your team puts into building, maintaining, and managing the web data solution, from high (fully DIY) to low (mostly delegated).
Speed to value: How quickly your web data solution delivers meaningful results, from fast (immediate impact) to slow (longer setup and experimentation).
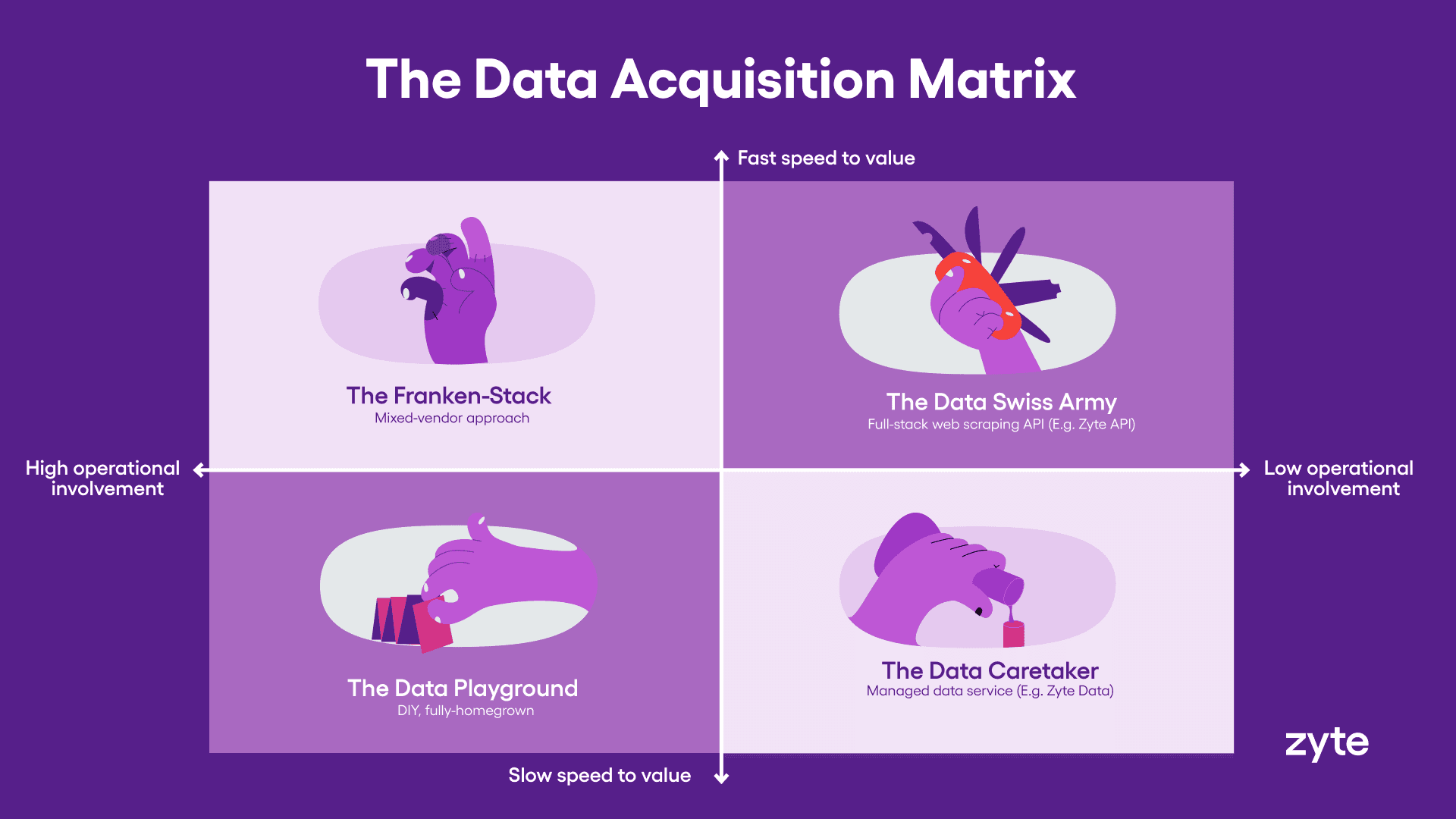
The Data Foundry requires high involvement and value can be slow to realize.
The Franken-Stack also demands considerable involvement (orchestrating, stitching, and leveraging existing solutions) but offers value more quickly.
The Swiss Army Knife offers fast speed to value through a unified user experience, and.
The Data Caretaker allows you to be virtually hands-off, with some initial collaboration required to align on business goals.
Weighing the factors
Where do you want to be on The Data Acquisition Matrix? As you decide which path to take, think about these considerations:
Technical engineering resources:
Do you have a dedicated team with deep expertise in web technologies, or would it be better to delegate the technical heavy lifting to an external provider?Project maturity:
Is your data project still in its experimental phase, or is it a fully developed system that drives key decisions? For early-stage projects, experimenting in-house within The Data Foundry and managing your own Franken-stack can help you understand costs and ROI. Once you've identified which parts can be delegated, you can use your Data Swiss Army Knife to streamline the process. When you’ve proven ROI but run into scaling issues that pull your team away from more valuable work, partnering with a Data Caretaker can relieve you of day-to-day challenges and let you focus on your business.Opportunity cost:
Weigh the benefits of using internal resources for strategic initiatives versus maintaining a complex data collection pipeline. Consider what your team could do if they weren’t busy maintaining a data system. If building your own system pulls talent from core revenue activities, the cost might be higher than it appears. A managed data service or full-stack web scraping API approach may free up those talents to focus on core business activities.Scalability:
How many websites do you need to scrape? Are these sites popular and hard to maintain? Fully homegrown systems may struggle to scale if sites change their rules. Orchestrating a Franken-stack takes a level of dedication and could easily get hairy. A full-stack web scraping API or a managed service is built to handle heavy traffic and frequent updates.
Control versus delegation:
How much control do you want? If having every detail under your control is crucial, a fully DIY system might be worth it. But if you want the balance of keeping some operational control while letting experts handle the tedious heavy-lifting—a full-stack web scraping API can hit the sweet spot.
Zyte API or Zyte Data?
Each of the four options—DIY, mixed vendors, full-stack APIs, or fully managed data services—comes with distinct advantages and trade-offs. Your decision hinges on factors like your team's technical capacity, the maturity of your project, scalability demands, and the required balance between control and convenience.
Whichever path you choose, Zyte can help.
Zyte’s all-in-one API offers a full-stack suite of web scraping tools, while Zyte Data offers a fully managed web data subscription service. So, how do you choose?
Here’s an overview to help you decide.
| Aspect | Zyte API | Zyte Data |
|---|---|---|
| Technical Team Capacity | Works best if your team can handle API integrations and adjustments | Ideal if your team is focused on core product development and prefers fewer technical distractions |
| Project Maturity | Best for dynamic, experimental projects where requirements evolve frequently; provides flexibility to adjust crawling rules and extraction methods | Best for mature projects with proven ROI and stable requirements; provides reliable data feeds with little need for ongoing technical adjustments, allowing your team to focus on insights |
Conclusion
Web data acquisition isn’t a one-time, black-or-white decision—it’s an evolving strategy.
The right approach today may not be the best fit tomorrow. As your needs change, so too should your approach.
Whether you start with a DIY solution, shift to an API, or eventually delegate the process to experts, the goal is to align your data acquisition strategy with your business priorities and resource constraints.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
