
Handling JavaScript in Scrapy with Splash
A common roadblock when developing spiders is dealing with sites that use a heavy amount of JavaScript. Many modern websites run entirely on JavaScript and require scripts to be run in order for the page to render properly. In many cases, pages also present modals and other dialogues that need to be interacted with to show the full page. In this post, we’re going to show you how you can use Splash to handle JavaScript in your Scrapy projects.
What is Splash?
Splash is our in-house solution for JavaScript rendering, implemented in Python using Twisted and QT. Splash is a lightweight web browser that is capable of processing multiple pages in parallel, executing custom JavaScript in the page context, and much more. Best of all, it’s open-source!
Setting up Splash
The easiest way to set up Splash is through Docker:
$ docker pull scrapinghub/splash $ docker run -p 5023:5023 -p 8050:8050 -p 8051:8051 scrapinghub/splash
Splash will now be running on localhost:8050. If you’re using a Docker Machine on OS X or Windows, it will be running on the IP address of Docker’s virtual machine.
If you would like to install Splash without using Docker, please refer to the documentation.
Using Splash with Scrapy
Now that Splash is running, you can test it in your browser:
http://localhost:8050/
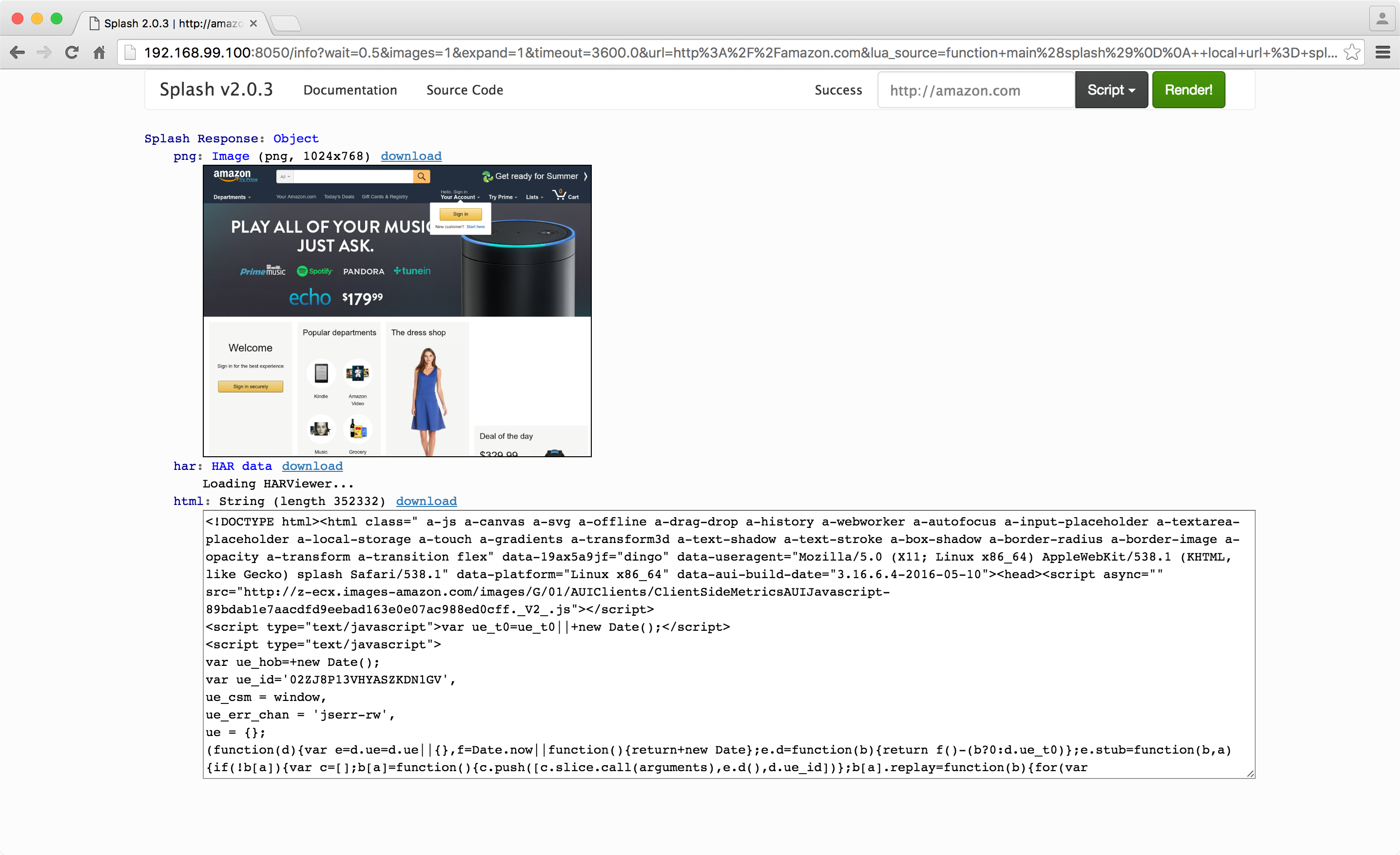
On the right enter a URL (e.g. http://amazon.com) and click 'Render me!'. Splash will display a screenshot of the page as well as charts and a list of requests with their timings. At the bottom, you should see a text box containing the rendered HTML.
Manually
You can use Request to send links to Splash:
req_url = "http://localhost:8050/render.json"
body = json.dumps({
"url": url,
"har": 1,
"html": 0,
})
headers = Headers({'Content-Type': 'application/json'})
yield scrapy.Request(req_url, self.parse_link, method='POST', body=body, headers=headers)
If you’re using CrawlSpider, the easiest way is to override the process_links function in your spider to replace links with their Splash equivalents:
def process_links(self, links):
for link in links:
link.url = "http://localhost:8050/render.html?" + urlencode({ 'url' : link.url })
return links
Scrapy-Splash (recommended)
The preferred way to integrate Splash with Scrapy is using scrapy-splash. See here for why it's recommended you use the middleware instead of using it manually. You can install scrapy-splash using pip:
pip install scrapy-splash
To use scrapy-splash in your project, you first need to enable the middleware:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
The middleware needs to take precedence over HttpProxyMiddleware, which by default is at position 750, so we set the middleware positions to numbers below 750.
You then need to set the SPLASH_URL setting in your project's settings.py:
SPLASH_URL = 'http://localhost:8050/'
Don’t forget, if you’re using a Docker Machine on OS X or Windows, you will need to set this to the IP address of Docker’s virtual machine, e.g.:
SPLASH_URL = 'http://192.168.59.103:8050/'
Enable SplashDeduplicateArgsMiddleware to support cache_args feature: it allows to save disk space by not storing duplicate Splash arguments multiple times in a disk request queue. If Splash 2.1+ is used the middleware also allows saving network traffic by not sending these duplicate arguments to Splash server multiple times.
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
Scrapy currently doesn’t provide a way to override request fingerprints calculation globally, so you will also have to set a custom DUPEFILTER_CLASS and a custom cache storage backend:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
If you already use another cache storage backend, you will need to subclass it and replace all calls to scrapy.util.request.request_fingerprint with scrapy_splash.splash_request_fingerprint.
Now that the Splash middleware is enabled, you can use SplashRequest in place of scrapy.Request to render pages with Splash.
For example, if we wanted to retrieve the rendered HTML for a page, we could do something like this:
import scrapy
from scrapy_splash import SplashRequest
class MySpider(scrapy.Spider):
start_urls = ["http://example.com", "http://example.com/foo"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, self.parse,
endpoint='render.html',
args={'wait': 0.5},
)
def parse(self, response):
# response.body is a result of render.html call; it
# contains HTML processed by a browser.
# …
The ‘args’ dict contains arguments to send to Splash. You can find a full list of available arguments in the HTTP API documentation. By default, the endpoint is set to ‘render.json’, but here we have overridden it and set it to ‘render.html’ to provide an HTML response.
Running custom JavaScript
Sometimes you may need to press a button or close a modal to view the page properly. Splash lets you run your own JavaScript code within the context of the web page you’re requesting. There are several ways you can accomplish this:
Using the js_source parameter
You can use the js_source parameter to send the JavaScript you want to execute. The JavaScript code is executed after the page finished loading but before the page is rendered. This allows using the JavaScript code to modify the page being rendered. For example, you can do it with Scrapy-Splash:
# Render page and modify its title dynamically
yield SplashRequest(
'http://example.com',
endpoint='render.html',
args={'js_source': 'document.title="My Title";'},
)
Splash scripts
Splash supports Lua scripts through its execute endpoint. This is the preferred way to execute JavaScript as you can preload libraries, choose when to execute the JavaScript, and retrieve the output.
Here’s an example script:
function main(splash)
assert(splash:go(splash.args.url))
splash:wait(0.5)
local title = splash:evaljs("document.title")
return {title=title}
end
You need to send that script to the execute endpoint, in the lua_source argument.
This will return a JSON object containing the title:
{
"title": "Some title"
}
Every script requires a main function to act as the entry point. You can return a Lua table that will be rendered as JSON, which is what we have done here. We use the splash:go function to tell Splash to visit the URL. The splash:evaljs function lets you execute JavaScript within the page context, however, if you don't need the result you should use splash:runjs instead.
You can test your Splash scripts in your browser by visiting your Splash instance’s index page (e.g. http://localhost:8050/). It’s also possible to use Splash with IPython notebook as an interactive web-based development environment, see here for more details.
It’s often the case that you need to click a button before the page is displayed. We can do that using splash:mouse_click function:
function main(splash)
assert(splash:go(splash.args.url))
local get_dimensions = splash:jsfunc([[
function () {
var rect = document.getElementById('button').getClientRects()[0];
return {"x": rect.left, "y": rect.top}
}
]])
splash:set_viewport_full()
splash:wait(0.1)
local dimensions = get_dimensions()
splash:mouse_click(dimensions.x, dimensions.y)
-- Wait split second to allow event to propagate.
splash:wait(0.1)
return splash:html()
end
Here we use splash:jsfunc to define a function that will return the element coordinates, then make sure the element is visible with splash:set_viewport_full, and click on the element. Splash then returns the rendered HTML.
You can find more info on running JavaScript with Splash in the docs, and for a more in-depth tutorial, check out the Splash Scripts Tutorial.
We hope this tutorial gave you a nice introduction to Splash, and please let us know if you have any questions or comments!