Improving access to Peruvian Congress bills with Scrapy
Many governments worldwide have laws enforcing them to publish their expenses, contracts, decisions, and so forth, on the web. This is so the general public can monitor what their representatives are doing on their behalf.
However, government data is usually only available in a hard-to-digest format. In this post, we'll show how you can use web scraping to overcome this and make government data more actionable.
Congress Bills in Peru
For the sake of transparency, Peruvian Congress provides a website where people can check the list of bills that are being processed, voted and eventually become law. For each bill, there’s a page with its authorship, title, submission date and a brief summary. These pages are frequently updated when bills are moved between commissions, approved and then published as laws.
By having all of this information online, lawyers and the general public can potentially inspect bills that could be the result of lobbying. In Peruvian history, there have been many laws passed that were to benefit only one specific company or individual.
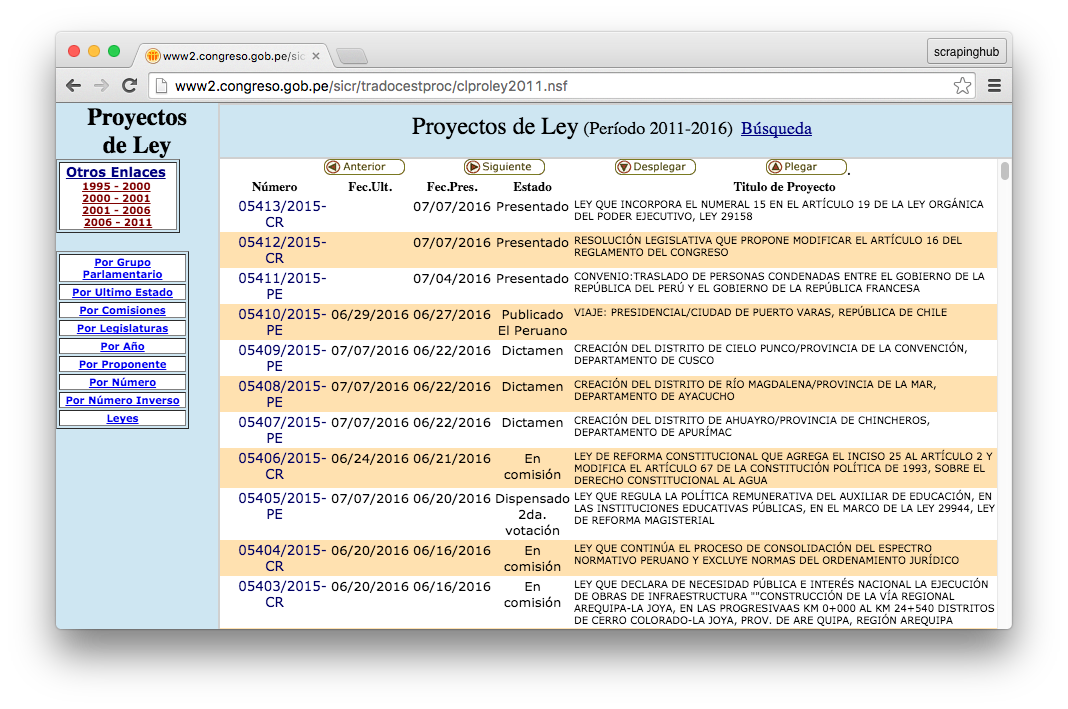
However, having transparency doesn’t mean it’s accessible. This site is very clunky, and the information for each bill is spread across several pages. It displays the bills in a very long list with far too many pages, and until very recently there has been no way to search for specific bills.
In the past, if you wanted to find a bill, you would need to look through several pages manually. This is very time consuming as there are around one thousand bills proposed every year. Not long ago, the site added a search tool, but it’s not user-friendly at all:
The Solution
My lawyer friends from the Peruvian NGOs Hiperderecho.org and Respeto.pe asked me about the possibilities to build a web application. Their goal was to organize all the data from the Congress bills, allowing people to easily search and discover bills by keywords, authors and categories.
The first step in building this was to grab all bill data and metadata from the Congress website. Since they don’t provide an API, we had to use web scraping. For that, Scrapy is a champ.
I wrote several Scrapy spiders to crawl the Congress site and download as much data as possible. The spiders wake up every 8 hours and crawl the Congress pages looking for new bills. They parse the data they scrape and save it into a local PostgreSQL database.
Once we had achieved the critical step of getting all the data, it was relatively easy to build a search tool to navigate the 5400+ bills and counting. I used Django to create a simple interface for users, and so ProyectosDeLey.pe was born.
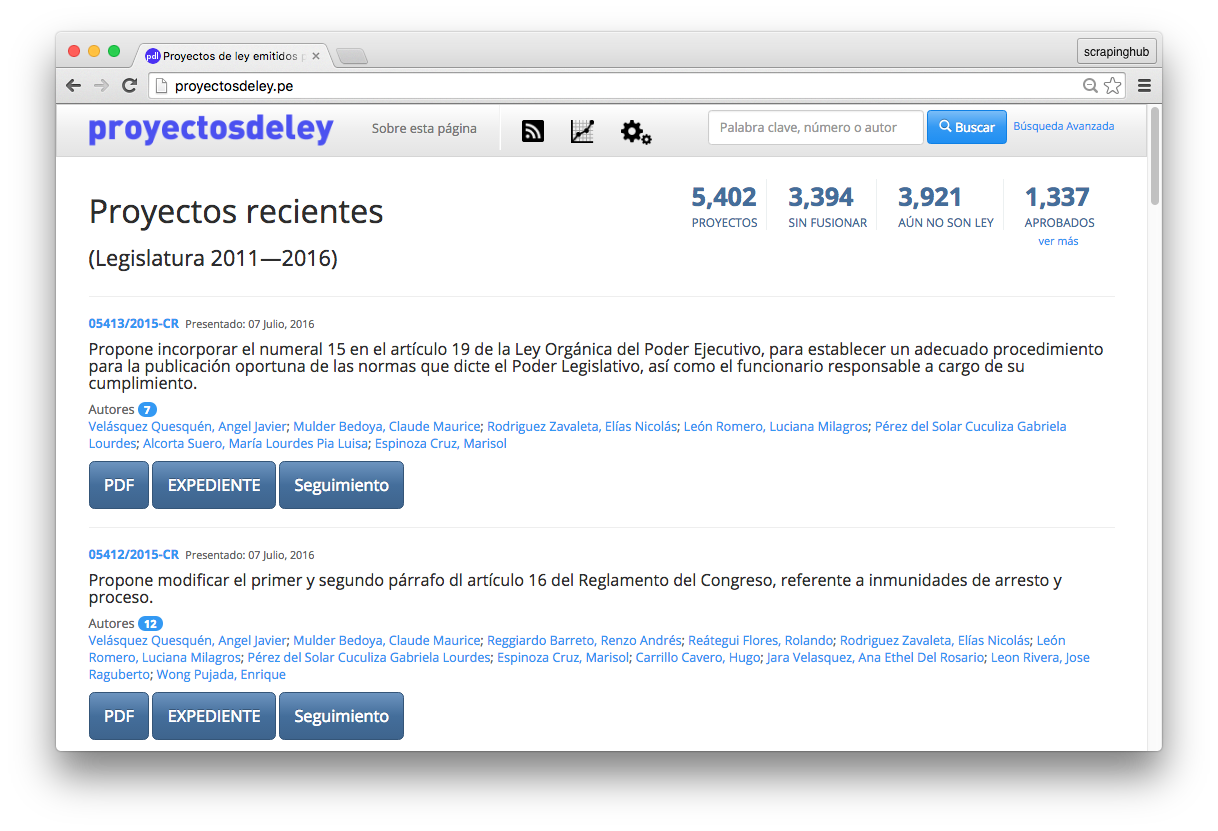
The Findings
All kinds of possibilities are open once we have the data. For example, we could now generate statistics on the status of the bills. We found that of the 5402 proposed bills, only 740 became laws, meaning most of the bills were rejected or forgotten on the pile and never processed.
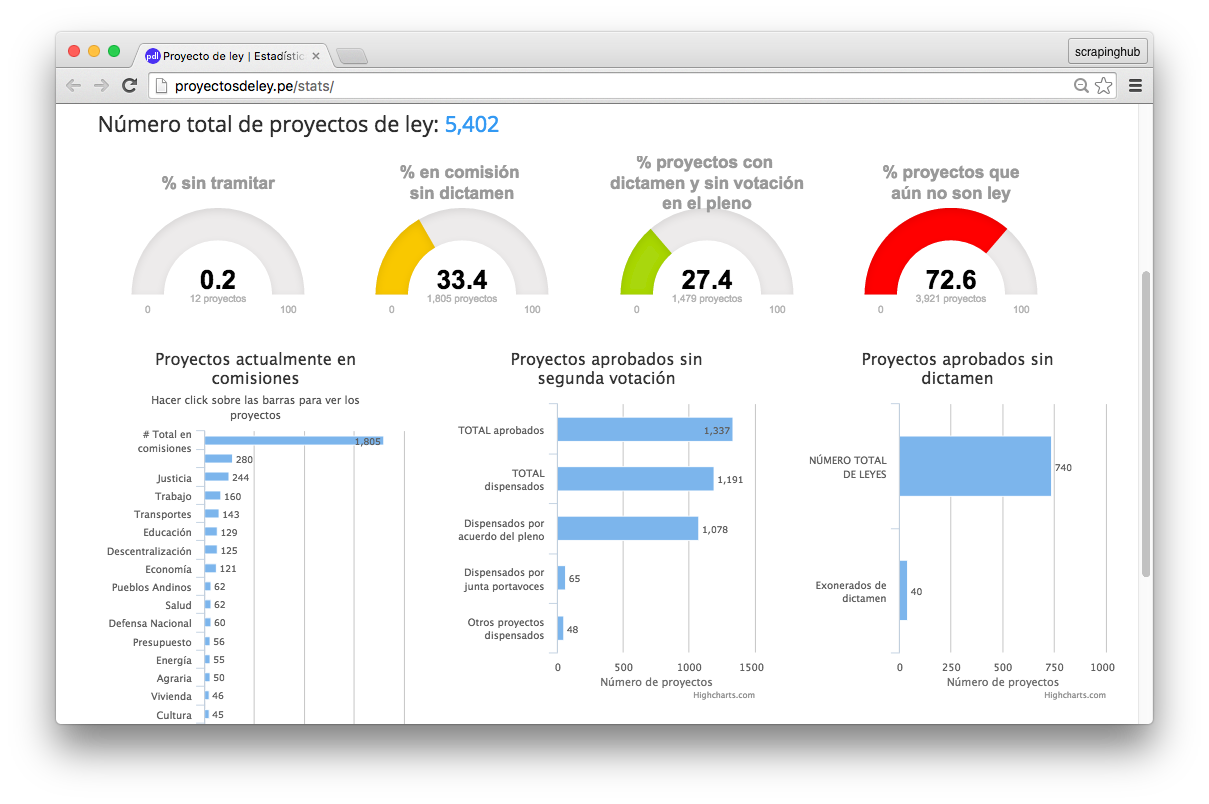
Quick searches also revealed that many bills are not that useful. A bunch of them are only proposals to turn some specific days into "national days".
There are proposals for national day of peace, "peace consolidation", "peace and reconciliation", Peruvian Coffee, Peruvian Cuisine, and also national days for several Peruvian produce.
There were even more than one bill proposing the celebration of the same thing, on the very same day. Organizing the bills into a database and building our search tool allowed people to discover these redundant and unnecessary bills.
Call In the Lawyers
After we aggregated the data into statistics, my lawyer friends found that the majority of bills are approved after only one round of voting. In the Peruvian legislation, dismissal of the second round of voting for any bill should be carried out only under exceptional circumstances.
However, the numbers show that the use of one round of voting has become the norm, as 88% of the bills approved were only done so in one round. The second round of voting has been created to compensate for the fact that the Peruvian Congress has only one chamber were all the decisions are made. It’s also expected that members of Congress should use the time between first and second voting for further debate and consultation with advisers and outside experts.
Bonus
The nice thing about having such information in a well-structured machine-readable format, is that we can create cool data visualizations, such as this interactive timeline that shows all the events that happened for a given bill:
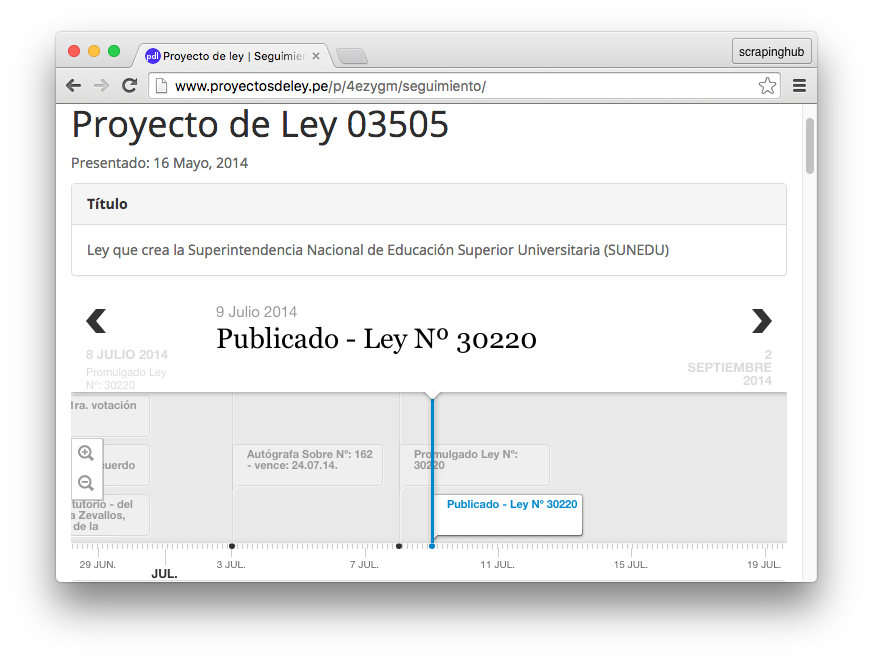
Another cool thing is that this data allows us to monitor Congress’ activities. Our web app allows users to subscribe to a RSS feed in order to get the latest bills, hot off the Congress press. My lawyer friends use it to issue "Legal Alerts" in the social media when some of the bills intend to do more wrong than good.
Wrap Up
People can build very useful tools with data available on the web. Unfortunately, government data often has poor accessibility and usability, making the transparency laws less useful than they should be. The work of volunteers is key in order to build tools that turn the otherwise clunky content into useful data for journalists, lawyers and regular citizens as well. Thanks to open source software such as Scrapy and Django, we can quickly grab the data and create useful tools like this.
See? You can help a lot of people by doing what you love! 🙂