
When LLMs aren't enough to scale web scraping
If you’re not using AI, you’re being left behind. Ever since ChatGPT burst onto the scene, this is the message developers are constantly hearing. AI can solve all the problems, but there’s little guidance on how to use it effectively. AI is a broad topic, but when it comes to web scraping, it involves machine learning (ML), natural language processing (NLP), computer vision, and large language models (LLM).
Web scraping is a time-consuming and challenging task that requires specialized knowledge and skills. It’s logical to think that AI would be the perfect tool to increase speed and accuracy in your web scraping projects. The buzz makes it sound like AI is the holy grail and the answer to our problems. How much of this is hype?
At Zyte, we’ve asked this question of ourselves. If LLMs aren’t the answer to increasing speed and accuracy in our projects and overcoming website bans (yet), what is?
Large language models alone are not the answer
Scaling up web scraping on hard-to-crawl websites at high volumes with high quality is problematic for multiple reasons. Traditional rules-based extraction is difficult, slow and costly. Teams are so bogged down in managing and maintaining existing spiders and infrastructure that they cannot grow or experiment with new data sources or websites. Hand-crafted site-specific code is slow to make and hard to scale. These issues kill a business's agility, and there is no way for them to dramatically increase output without hiring more developers.
LLMs are general systems and aren’t built to be a complete web scraping solution. By their nature, general systems result in large models that require substantial processing power to run, and that’s reflected in the price. That’s why using LLMs in most situations is not cost-effective when traditional rules-based extraction is cheaper.
Reliability challenges are one of the major issues with LLMs. They hallucinate, and it’s not always clear how to fix errors and control quality. Many people are experimenting with LLMs (just look at the ChatGPT store), but there’s no killer app yet. Why? LLMs in web scraping must integrate into other solutions for website bans and rendering. Some apps can do parts of this, but not all.
And what if we made an AI specifically for web scraping?
General LLMs like ChatGPT aren’t a complete solution to the scaling problem. Considering LLMs' speed, control, cost and quality limitations, we created our own ML model trained to extract structured data from most websites and integrate it within a web scraping API that already solves website bans. Unlike a general LLM, Zyte API’s ML model is
patented, mature and can scale,
smaller to run,
50x cheaper,
more accurate than larger LLMs,
self-healing by adapting to changes in website layouts without maintenance,
compliant as our standard schemas exclude sensitive data like PII and copyrighted content, and
highly accurate because it uses a human-in-the-loop to correct site-specific issues and retrain the model on specific edge cases.
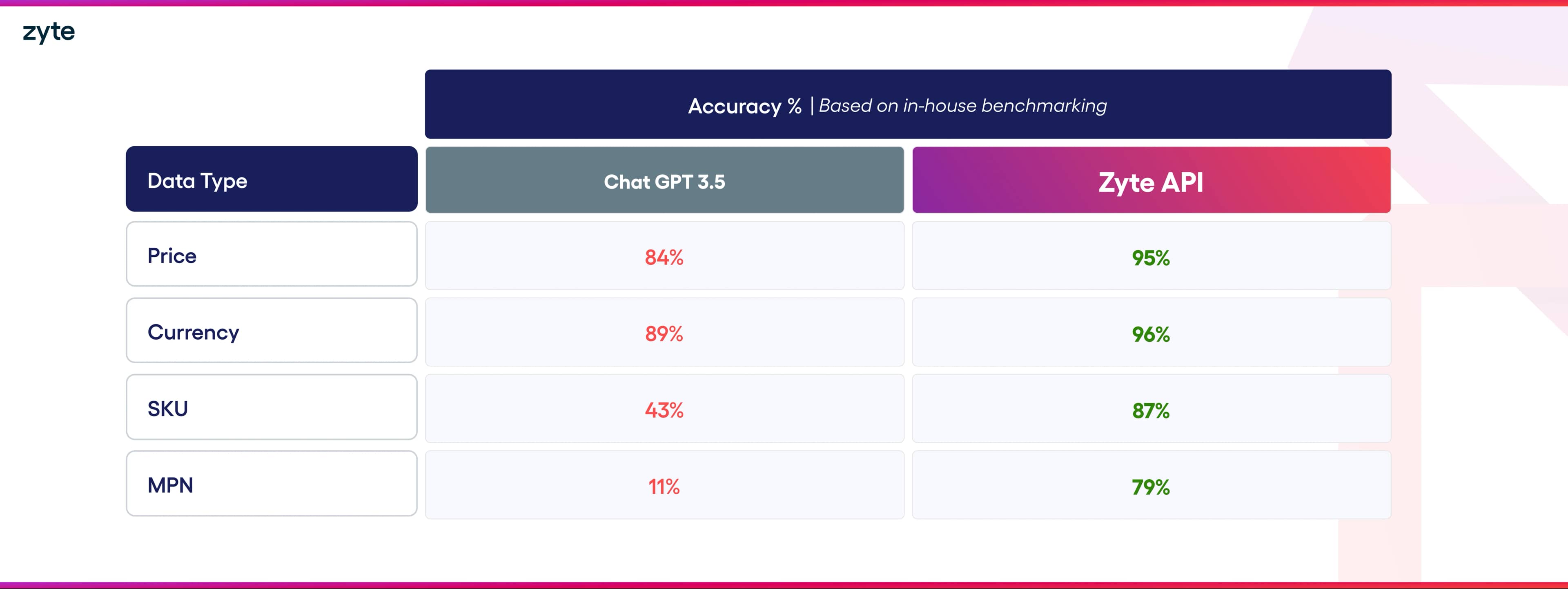
From our internal benchmarking, Zyte API can extract data faster and more accurately than ChatGPT.
The Zyte AI Stack
So, we have a supervised ML model built for extracting structured data in Zyte API. Where in the web scraping stack does this help in your projects? Let’s break down the Zyte AI Stack.

AI crawling with complete control
Zyte API is built upon Scrapy, the world’s most popular scraping framework. We’ve created spider templates that harness Zyte API’s AI features to unblock and automate from end to end. Simply run the templates as is for instant data, as our AI is trained to recognize all common and uncommon navigation patterns.
The Zyte AI Stack starts with open sourced AI-powered Scrapy templates that call Zyte API’s libraries and ML models. These libraries and ML models automate crawling, extraction, and website bans. Scrapy Cloud UI gives developers another way to run AI-powered spiders in the cloud and create new spiders based on the template.
This automatic extraction eliminates figuring out a website’s navigation templates, URL structures, or pagination. However, for complete control, you can fork the open-source spider templates and edit them in Python to do things like adjust the crawling strategy, extend and change the schema, or manage quality.
Parsing and extracting data with AI
Zyte API patented ML model extracts data into legally compliant schemas without the time-intensive task of writing and rewriting xpaths or selectors. We taught our model to find structured data without coding the instructions, making it quick and unbreakable.
Zyte uses a supervised ML model for extracting structured text, but we recognize that getting data from unstructured text is best suited to LLMs like ChatGPT. It’s not practical and scalable to train a model to recognize data from unstructured text from the thousands of websites available. Our data services team uses LLMs in addition to Zyte’s AI stack to extract data in these complicated use cases. These situations make LLM usage cost-effective.
Overcoming website bans to allow AI to access
LLMs can’t automatically solve website bans, but Zyte API’s robust automated ban-handling functionality can. What are the best data extraction models to use if you can’t access the data in a scalable, cost-effective, and reliable way? Zyte API ensures our AI can access websites at scale reliably, even if they change anti-bot protection.
No matter how good the AI is, it must unblock the difficult-to-scrape websites
The best AI in the world, whether it’s LLMs or ML, is useless if you can’t access the website in the first place. Any AI-powered tool being considered as a complete solution to web scraping with AI must:
provide developers with complete control over their spiders,
leverage a developer’s existing skillset,
have a robust ban handling solution to ensure access for data extraction,
use automation to eliminate maintenance,
have strong integration with the biggest web scraping frameworks being used in the industry,
have models that can be used on any site and aren’t limited to specific sites only,
be cost-effective,
eliminate the need to juggle multiple tools with different pricing strategies, and
be legally compliant.
Zyte API is a complete end-to-end AI-powered Web Scraping Solution
We believe any business or team that relies too heavily on hand-crafted spiders to unlock speed and scale is inefficient and unable to scale quickly.
Zyte API will save you vast amounts of time, money, and stress when collecting web data and set your most skilled people free to focus on customizing and fine-tuning collection and extracting value from the data rather than just extracting it from the web.
Start scraping with AI, and start a free trial with Zyte API. Check our docs for more information.
FAQs
Why aren’t LLMs enough?
High cost, low accuracy, and inability to handle challenges like bans or dynamic pages.
Why is Zyte API better?
Tailored ML model: faster, 50x cheaper, self-healing, and compliant.
How does Zyte AI Stack help?
Automates crawling and extraction.
Customizable templates and robust ban handling.
Where do LLMs fit?
Best for complex unstructured text; used selectively with Zyte AI.
Why use Zyte API?
End-to-end, scalable, cost-effective, and easy to integrate.