
Looking back at 2013
This time last year Pablo and I were chatting about the previous year and what to expect in 2013. I noticed that our team had almost doubled in size in the previous year and we wondered could that possibly continue in 2013?
It turns out it did! We went from 20 team members to almost 40 and the number of projects, customers, etc. all doubled. We've become even more distributed as we've grown, covering 19 countries:
 Click for interactive map of current team
Click for interactive map of current team
What the numbers don't show is that these new hires have become indispensable members of the team and it's hard to imagine working without them.
Over 2 billion web pages were scraped using our platform in 2013! We're pleased this was done politely, without receiving a single complaint. More users participated in our beta and we saw a 4x growth in our platform usage[1]:
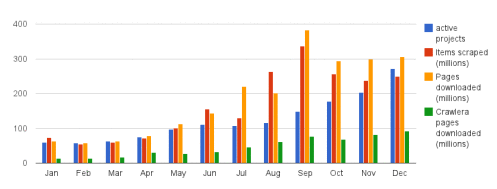
This would not have been possible without our new architecture, for reasons explained in our most popular blog post of 2013.
Our open source contributions increased - we had 2 large stable Scrapy releases (0.18 and 0.20) and started several new projects (e.g. splash, webstruct, webpager, scrapyjs and loginform). Scrapy usage (github stars, forks, etc.) doubled again this year and is currently number 12 in github's trending python repositories this month. We have more exciting releases planned, such as a new open source annotation UI for Autoscraping and Scrapy 1.0!
We are very proud of our team and what we have achieved this year. We would like to thank all our customers and supporters. Happy New Year everyone!