
Looking back at 2015
2015 has been a standout year for Zyte with new developments in expanded products, noteworthy clients, and cherished partnerships. We were curious about whether we could continue our growth from 2014 and are pleased to report that our curiosity has been successfully laid to rest. So without further ado, let’s dive straight into what has made 2015 a hard act to follow.
5 Year Anniversary
First of all, we turned 5 on December 15. In a competitive startup world with a failure rate of 90%, we are solidly in the successful 10% that made it past the high attrition period. This is a huge milestone and, while it’s debatable when we actually graduated into the established company category, I think it’s safe to say that we’re here to stay. We’ve also managed to retain our core company culture of remote work and distributed team members while toiling through the growing pains of the startup scene.

Platform
One of the major causes of failure cited for startups is a lack of market interest for the product. We attribute a major part of our success to not only having a highly prized set of tools that help you scrape the web efficiently, but we take it a step further by offering customized solutions for every need. Our ability to deliver new and innovative technology like Splash and Frontera has continued to set us apart from the competition.
Scrapy Cloud and Crawlera
This has been a high growth year for Scrapy Cloud. We scraped and stored data from over 22 billion pages (2 times the amount of last year) and we ran 18M crawler jobs (4 times the number of 2014 and 22 times that of 2013). There were over 20 billion pages that passed through Crawlera this year (4 times the amount of last year) with an increasing number of users discovering our platform.
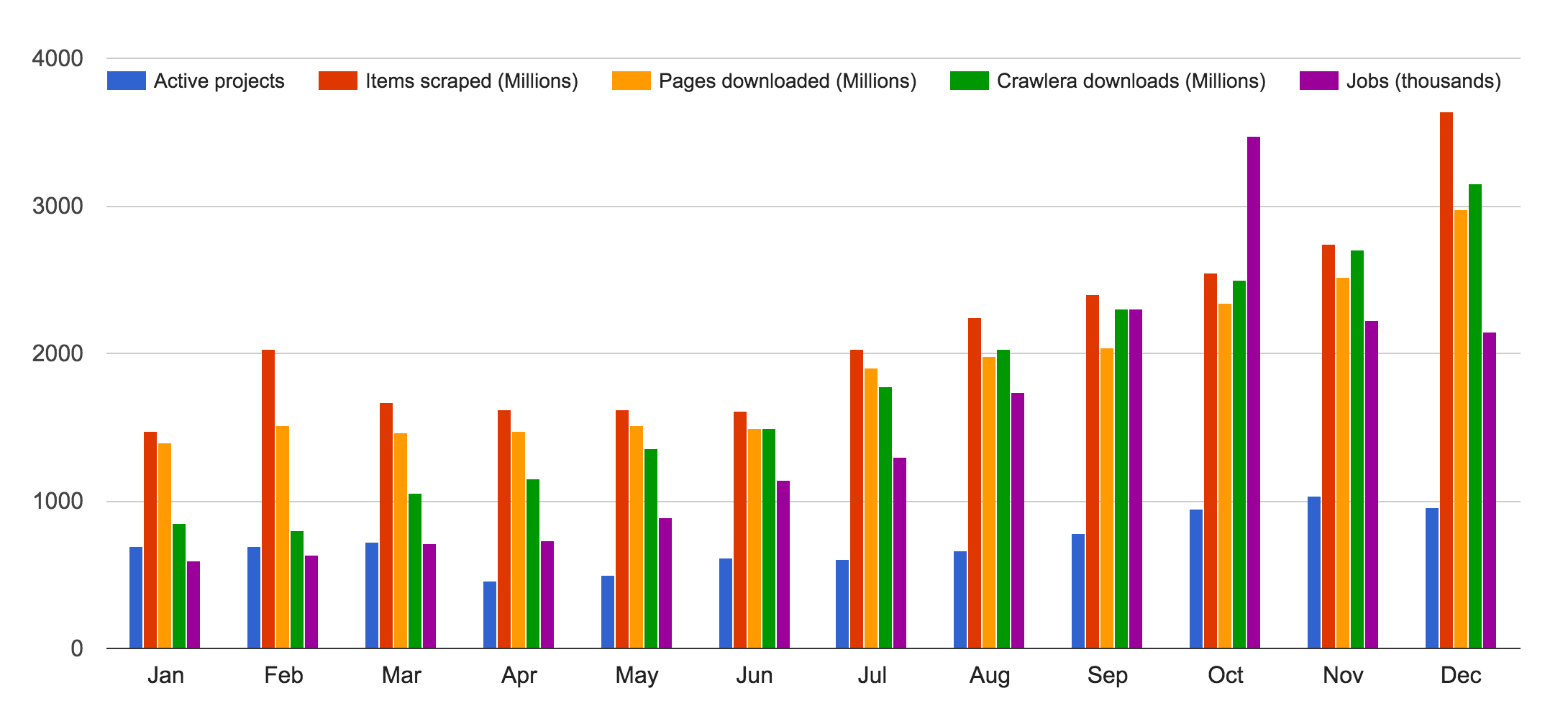
We're really scaling up our crawling jobs this year!
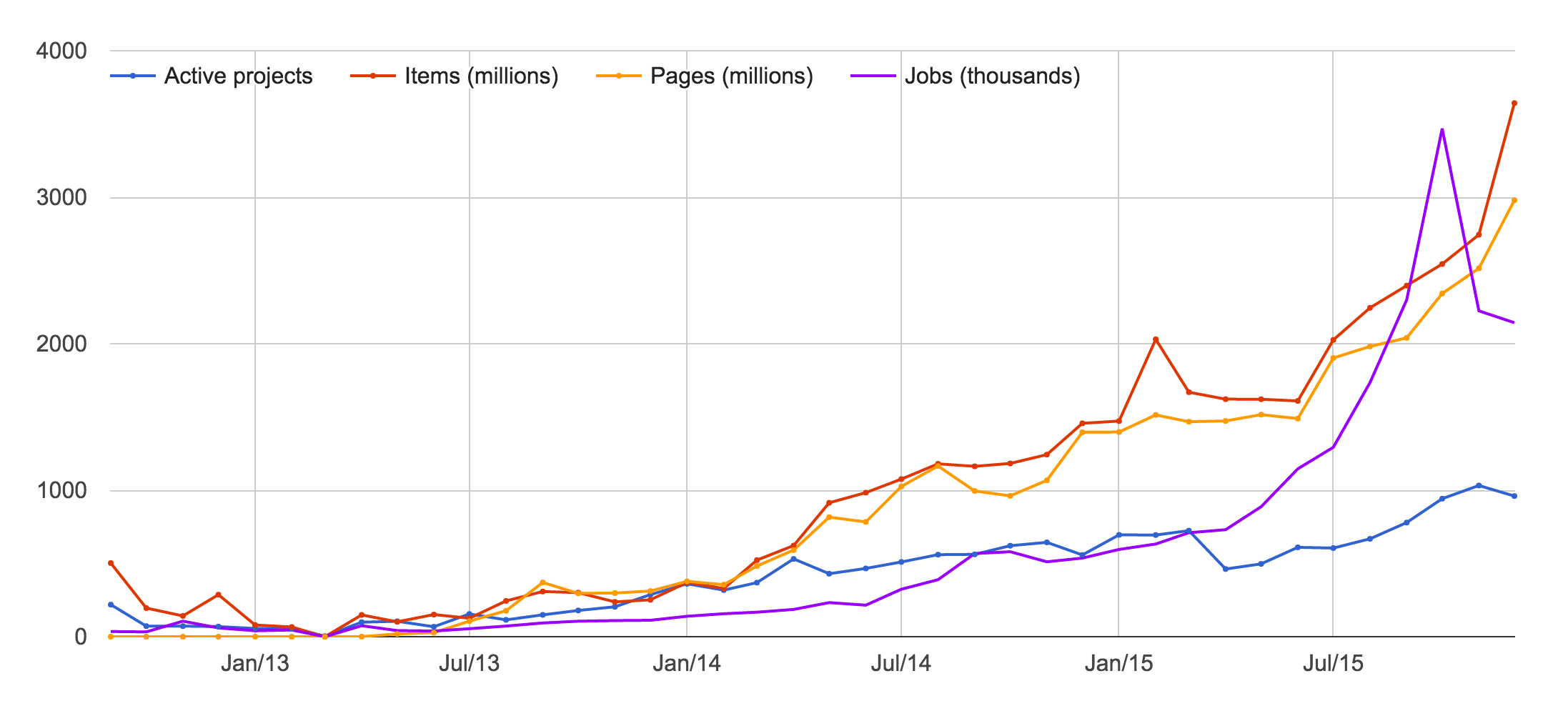
Our technology and tools are evolving rapidly to keep up with the growing demand.
Frontera
In 2015, Frontera grew from a small library that implemented simple crawling strategies like FIFO/LIFO and was only suitable for single process usage to a much bigger web crawling toolbox. It now contains a transport layer (by means of Apache Kafka or ZeroMQ) and a more powerful backend concept. This backend concept allows you to separate crawling policies from low-level storage-specific code. The new HBase backend is also geared for high performance crawling. Finally, we ran a stress test crawl of 45 million documents from about 100K websites in the .es zone and presented our findings in 4 conferences. Over the last few months, we’ve been working on making Frontera easier to use as well as adding helpful features, so expect a new release with a smaller configuration footprint and more accessible documentation in the near future.
Portia
This has been a bumper year for Portia. We’ve made many changes that have allowed you to build spiders more quickly and much more easily. At the beginning of the year, we addressed user feedback and simplified the annotation process.
To the delight of many of you Portia users, during the summer we added support when creating spiders for sites that require JavaScript. Along with this release, we added the ability to record actions on a page and execute them during a crawl. Another new feature of Portia is the addition of algorithms that make suggestions for information on the page that you may want to annotate.
We have been working hard behind the scenes on the future of Portia, so be on the lookout in 2016 for a new user interface (UI) designed to make creating spiders a breeze. With this new UI, you will be able to easily extract many items from a single page with even more advanced annotation suggestions.
Open Source Releases
We’ve deployed a number of open source projects this year, all aimed at improving scraping techniques for polite data extraction.
-
- Aile is a project that we’ve created to experiment with automated list extraction
-
- Flatson is a library for flattening data into a table-like format when given a JSON schema
-
- Extruct is a library for extracting embedded metadata from HTML documents
Scrapy also had its 1.0 release and has an ongoing Python 3 port. From this process emerged Parsel, an lxml-based library used for extracting data from HTML/XML documents, along with a bunch of Scrapy plugins. We’ve given these Scrapy plugins a new home!
We have continued to improve other projects, including Dateparser (which now runs in PyPy and Python 3) and Splash.
Booths Galore
We really hit the road this year with 15 conferences and 12 talks scattered around the world. We went everywhere from PyCon Philippines to EuroPython to PyCon Russia. We had booths in 4 conferences, including Python Brasil (featuring some pretty sweet swag). A couple of our Zytebers also reached out to their local communities either by leading an Hour of Code or being a part of BIME Hack Day.

Check out the sheer concentration of swag with the largest meeting of Zytebers ever for EuroPython
Google Summer of Code
This past summer was our second year participating in Google Summer of Code. We worked with students under the umbrella of the Python Software Foundation and one is now a dedicated Zyteber. We’re always looking for new ways to cultivate interest in and understanding of Python and our scraping technologies, and this provided a wonderful opportunity for us to act as mentors. We’re psyched to lead a Google Summer of Code program in 2016, so keep an eye out for fun project proposals.
Zyte is on the Rise
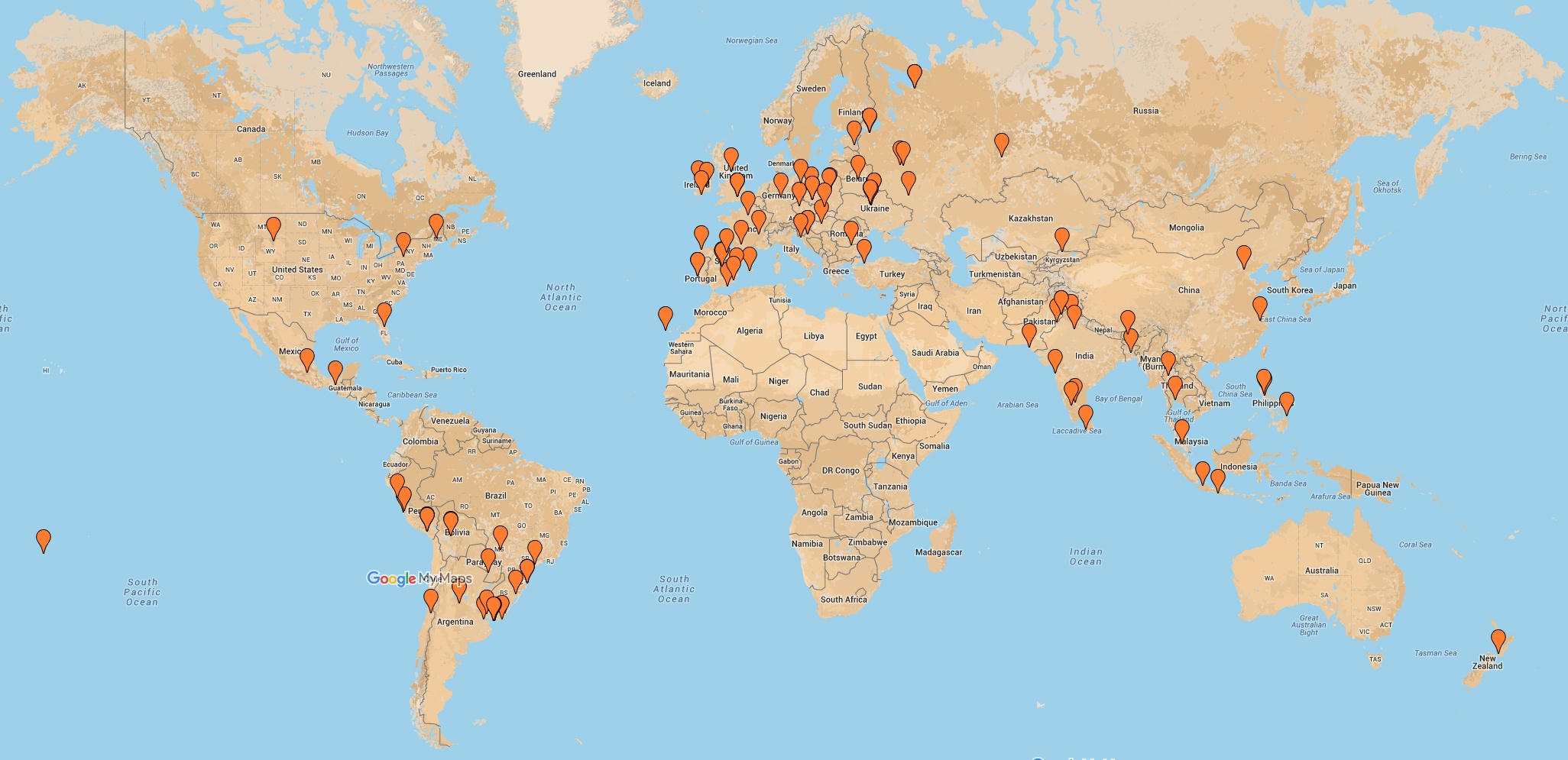
Our Zyteber community has continued to grow and there are now Zytebers in 36 countries. We were 85 at the end of last year and we’re at 119 team members in December with 6 more to come just in January alone! We’re thrilled with the talents that each of our new hires has brought to their established teams.
In fact, our team has grown so much in the last couple of years that we decided to create a dedicated Human Resources team to take on the bulk of the HR logistics. Some of the challenges that the Zyte HR team has faced include the rapid expansion of the company and the multicultural and distributed nature of our team.
This year we’ve enacted some perks to help our Zytebers achieve new heights in their careers. Starting this year, our crew has access to a hardware allowance and an online course stipend to help with professional development.
Cheers
A huge thank you to our Zyte team, our wonderful clients, and the open source community that works with us to make our products even stronger.
That wraps up 2015, which has been monumental in so many ways. So cheers to 2016, I can’t even begin to imagine where we’ll go from here!