
News data extraction at scale with AI-powered Zyte Automatic Extraction
A huge portion of the internet is news. It’s a very important type of content because there are always things happening either in our local area or globally that we want to know about.
The amount of news published every day on different sites is ridiculous.
Sometimes it’s good news and sometimes it’s bad news but one thing’s for sure: it’s humanly impossible to read all of it every day.
In this article, we take you through how to extract data from two popular news sites and perform basic exploratory analysis on the articles to find some overarching theme across news articles and maybe even news sites.
Going through this article you will get some insights about our newest AI data extraction tool - Zyte Automatic Extraction (formerly AutoExtract), and how it can be used to extract news data without writing any XPath or selectors.
You will also learn some easy-to-do but spectacular methods to analyze text data. The exact process we are going to follow, for each news site:
- Discover news URLs on the site
- Pass URLs to Zyte Automatic Extraction API
- Output data in JSON
- Analyze data
Discover news URLs on the site
Discovering URLs on the site is an essential first step because otherwise, we won’t have the input data that is needed for the Zyte Automatic Extraction API. This input data is the URL of a news article. Nothing else is needed. So first, let’s grab all the main page news article URLs. We need to set up a new Scrapy spider and use Scrapy’s Linkextractor to find the correct URLs:
class NewsSpider(Spider): name = "news" start_urls = ["somenewsite.com"] def parse(self, response)í: extractor = LinkExtractor(restrict_css=".headline-text") urls = [link.url for link in extractor.extract_links(response)]
Pass URLs to Zyte Automatic Extraction (formerly AutoExtract) API
Now that we’ve got the URLs we can go ahead and use the Zyte Automatic Extraction API. These are the things you need to have, packaged in a JSON object, to make an API request:
- Valid API key (Sign up for free to get one!)
- pageType (product or article)
- URL
This is how the Zyte Automatic Extraction API call should look like, inside Scrapy:
xod = "https://autoextract.scrapinghub.com/v1/extract" headers = {"Authorization": basic_auth_header(, ""), "Content-Type": "application/json"} params = [{"pageType": "article", "url": url}] req = Request(xod, method="POST", body=json.dumps(params),headers=headers, callback=self.callback_func)
Adding this piece of code to our previously created spider:
def parse(self, response):
extractor = LinkExtractor(restrict_css=".headline-text")
urls = [link.url for link in extractor.extract_links(response)]
xod = "https://autoextract.scrapinghub.com/v1/extract"
headers = {"Authorization": basic_auth_header(, ""), "Content-Type": "application/json"}
for url in urls:
params = [{"pageType": "article", "url": url}]
yield Request(xod, method="POST", body=json.dumps(params), headers=headers, callback=self.extract_news)
This function will first collect all the news article URLs on the main page using Scrapy’s LinkExtractor. Then we pass each URL, one by one, to the Zyte Automatic Extraction API. Zyte Automatic Extraction will get all the data that is associated with the article, for example, article body, author(s), publish date, language, and others. And the best part: without any HTML parsing or XPath.
Zyte Automatic Extraction (formerly AutoExtract) uses machine learning to extract all the valuable data points from the page and we don’t need to write locators manually. It also means that if the website changes the design or the layout we don’t need to manually change our code. It will keep working and keep delivering data.
Output data in JSON
In our API request, we use extract_news as the callback function. This callback function will parse the response of the API request, which is a JSON. This JSON contains all the data fields associated with the extracted article. Like headline, URL, authors, etc. Then we populate the Scrapy item.
def extract_news(self, response):
item = ArticleItem()
data = json.loads(response.body_as_unicode())
item["url"] = data[0]["article"].get("url")
item["text"] = data[0]["article"].get("articleBody")
item["headline"] = data[0]["article"].get("headline")
item["authors"] = data[0]["article"].get("authorsList")
return item
With this code above, we populated the ArticleItem with data from the Zyte Automatic Extraction API. Now we can just run the full spider and output the data for later analysis:
scrapy crawl news -o news_output.json
Analyzing the data
We were able to extract news data from the web. Even though, at this point, this is just pure data you might find it useful to be able to get news data from any website, anytime. Let’s go a little bit further and perform some exploratory data analysis on the extracted text.
Wordcloud
When it comes to text analysis one of the most popular visualization techniques is the word cloud. This kind of visualization is meant to show what words or phrases are used the most frequently in the given text. The bigger the word, the more frequently it is used. Perfect for us to learn what words are most commonly used in headlines and in the article itself.
Installing wordcloud and requirements
In python, there’s an open-source library to generate word clouds, wordcloud. This is a super easy-to-use library to create simple or highly customized word clouds (actual images). To use wordcloud we have to first install these libraries: numpy, pandas, matplotlib, pillow. And of course wordcloud itself. All these packages are easy to install with pip.
Generating a wordcloud
Let’s say we want to know what are the most common words in headlines on the homepage. To do this, first, we read data from the JSON file that Scrapy generated. Then we create a nice and simple wordcloud:
df = pd.read_json("news_output.json") cloud = WordCloud(max_font_size=80, max_words=100, background_color="white").generate(text) plt.imshow(cloud, interpolation='bilinear') plt.axis("off") plt.show()
News in the US vs the UK
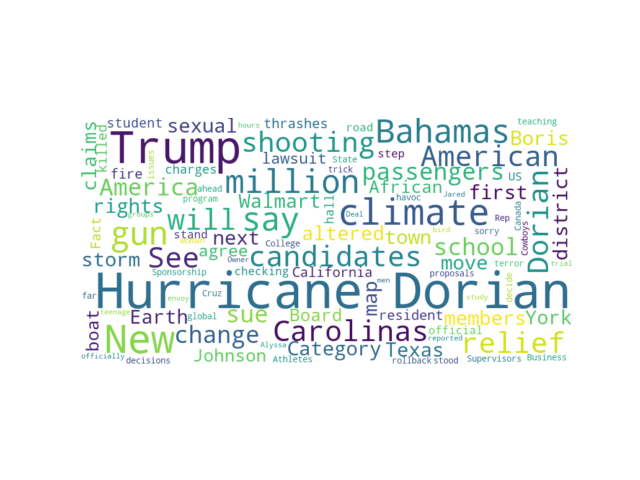
US news site homepage headlines
At the time of writing this article, it looks like the analyzed US news site puts a lot of focus on “Hurricane Dorian” in the headlines. There are a lot of news articles on this topic. The second most common word is “Trump”. Other frequently used words are: “American”, “Bahamas”, “million”, “Carolinas”, “climate”.
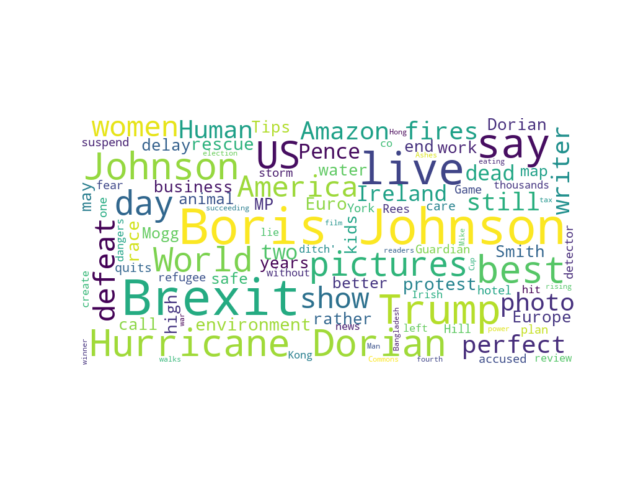
UK news site homepage headlines
The other website we extracted news from is one of the most visited UK news sites. Even without looking at the results, we could probably guess that the frequently used words on the UK site would differ from what we found on the US site. The most used words in the headlines are “Boris Johnson”, “Brexit”, “US”. Though there are similarities as well, “Hurricane Dorian” is frequently used here too, the same is true for “Trump”.
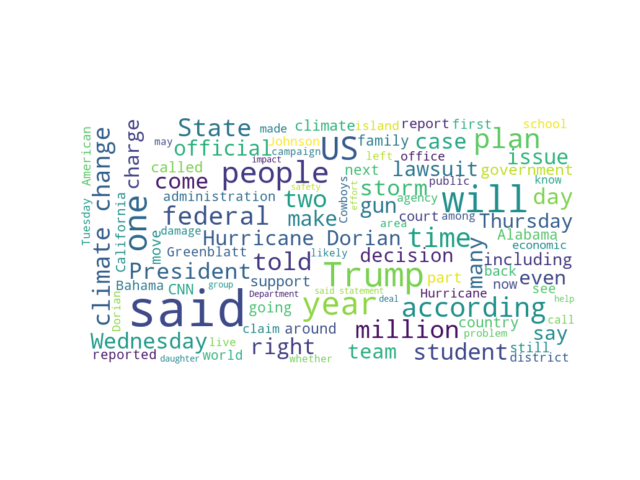 US news site homepage articles
US news site homepage articlesWhen analyzing not the headline but the article itself it becomes very noisy on the US news site. “Trump” is frequently used in the text as well. Other words are “said”, “will”, “people”, “year”. There’s not as big of a difference between the frequency of the words as we saw it with the headlines.
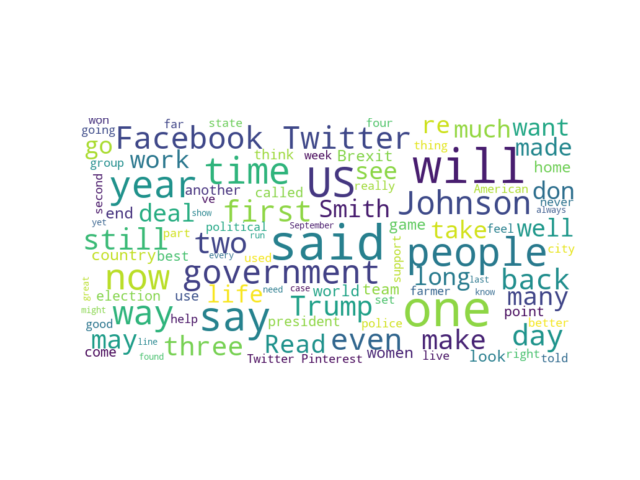 US news site homepage articles
US news site homepage articlesFor the UK news site, it’s less noisy. It looks like there are many words used relatively frequently. But it’s hard to choose only one or two. “People”, “Johnson”, “government”, “Trump”, “US” are among the most used words in articles.
.
Conclusion
I hope this article gave you some insights on how you can extract news from the web and what you could do with web scraped news data. If you are interested in our news data extraction tool, try out Zyte Automatic Extraction (formerly AutoExtract) here, on a 14-day free trial.
At the core of the Zyte Automatic Extraction is an AI-enabled data extraction engine able to extract data from a web page without the need to design custom code.


Through the use of deep learning, computer vision, and Zyte Smart Proxy Manager's , advanced proxy management solution, the data engine is able to automatically identify common items on product and article web pages and extract them without the need to develop and maintain extraction rules for each site.
Other verticals will be added to the API in the coming months.