
In too many customer calls, I kept hearing the same frustration from our customers: "We need data on our market from dozens of smaller websites, but the economics just don't work."
As Chief Product Officer at Zyte, this problem haunted me. Back in 2021, our customers couldn't find a solution anywhere in the market, and honestly, we couldn't offer one either. This is the story of how we finally cracked it.
The web data dilemma: why customers were forced to say no
Imagine you are a brand analytics provider. You have a customer, a major technology company, seeking competitive intelligence including product and price data from two major electronics retailers. Your customer needs specific on-page product fields — like, say, memory capacity or GPU brand — and the data must be highly accurate.
So far, so straightforward. But here’s the catch – your customer also needs listings from 15 much lesser-known sites.
Ninety percent of the product listings come from those two big sites but your client wants complete coverage.
Typical data feed setup costs at the time averaged $1,500 per site, whether for a large or small site. That could mean a total cost of $22,500 for all 17 sites. With the vast majority of this cost fetching just 10% of the data, the economics of complete coverage can look problematic.
Squaring the impossible pentagon
This scenario articulates a set of problems I've encountered numerous times in conversations with potential customers:
Setup – Even if a site yields relatively few records, its underlying markup may mean it is just as complex to set up, if not more so, than a high-volume source. But extracting data shouldn’t always require expensive, time-consuming engineering work.
Record cost – Whilst setup cost is a barrier to getting started, ongoing cost of records is a barrier to growth.
Site coverage – Data buyers need coverage from both popular sources and long-tail sites.
Data coverage – Industry-specific, non-negotiable data points must be available.
Data quality – Data buyers don’t want to compromise on data quality or specific fields. Reliable, decision-ready data is essential, not an afterthought.
This is a combinatorial problem that has not been well met in the market.
Off-the-shelf data bought from a data marketplace often lacks sufficient depth of product listings and data fields. For a web data provider like Zyte, solving these challenges is tough because each customer need is inter-related — and the solution for each may have its own trade-off.
For example:
Reducing initial setup costs could drive up ongoing per-record costs (e.g., generative AI models require more compute).
Allowing flexible data schemas would increase setup time and introduce engineering complexities.
Automating multiple-site extraction had to be labor-efficient or it wouldn’t scale.
This forced us to think differently. No single approach could solve everything.
The breakthrough came when we stopped seeing these as competing approaches. The key insight was learning to decompose each problem: identifying which parts were "kind problems" (structured, predictable, deterministic) versus "wicked problems" (complex, variable, probabilistic).
We needed a composite solution that applied different technologies to different parts of the problem.
The right tool for the right problem

Zyte's core technologies are rooted in a code-based approach built around the Scrapy ecosystem. In 2021 we introduced our first automatic extraction capabilities, built on top of homegrown computer vision-based supervised models. Then as the large language model (LLM) boom at the end of 2022 made web scraping accessible to a larger audience, we saw the potential to integrate them into our solutions.
When you have different tools to complete a task, one important thing to consider is the different cost structure of each approach so you can deploy it only where it is needed.
Writing custom code for everything gives you the most control but is time consuming and has a high setup cost per site. Relying on machine learning models specifically trained to extract a set of attributes saves engineering effort but can limit flexibility on customization. Running everything through LLMs is fast and easy but is too expensive and could yield unreliable results when used without proper techniques.
Based on these, we envisioned a system that used the best tool for the job:
Supervised AI for common, structured data. This is perfect for sites with a predictable structure, like product pages. We train our supervised models to grab common schemas for top data types like titles, prices, and descriptions. It’s fast, accurate, and covers a large portion of common needs.
Generative AI for flexible schema customizations. When data is buried in messy text or the customer needs something custom, we turn to large language models. These models can understand context and pull out specific details through their inherent albeit limited reasoning capabilities, even if the data points aren't neatly labeled on the page.
Custom code where necessary. For intricate and specialized crawling and extraction logic, we use Scrapy-based code. This gives us finely-tuned control over effectiveness and cost of the data collection.
From theory to practice: real business impact
This approach let us do what no one else in the market could:
Any site, any data
Thanks to this new approach, we now support scraping of more sites than ever before. We have everything we need to handle different types of data extraction requests. Customers can access the exact data they need without the rigidity of conventional scraping techniques or the brittleness of emerging low-code tools.
Economics that work
We've reduced setup time for common projects from an average of 24 hours per site to just three hours—low enough to absorb as a cost of sale for standard schemas. This creates a layered cost structure where customers pay only for the complexity they actually need.
Quality without compromise
Data quality is less of a tedious and costly process now. Our large language models perform automatic assessments on extracted data. When issues are detected, our point-and-click tools can be used to create site-specific hints that guide the AI without full custom coding.
Custom data made simple
The ability to mix standard schemas with custom extensions has been a game-changer. A customer needing 17 standard product fields plus 12 segment-specific fields no longer needs to code all 29 fields from scratch. Standard fields can be extracted instantly, with custom fields added selectively using either generative AI or targeted code.
Beyond web data: composite AI in other industries
While our approach of combining two types of AI to achieve these results in the web data extraction space is unique, the practice of combining different AI technologies to solve problems isn’t novel.
This approach is commonly known as composite AI and it has proven powerful across various industries.
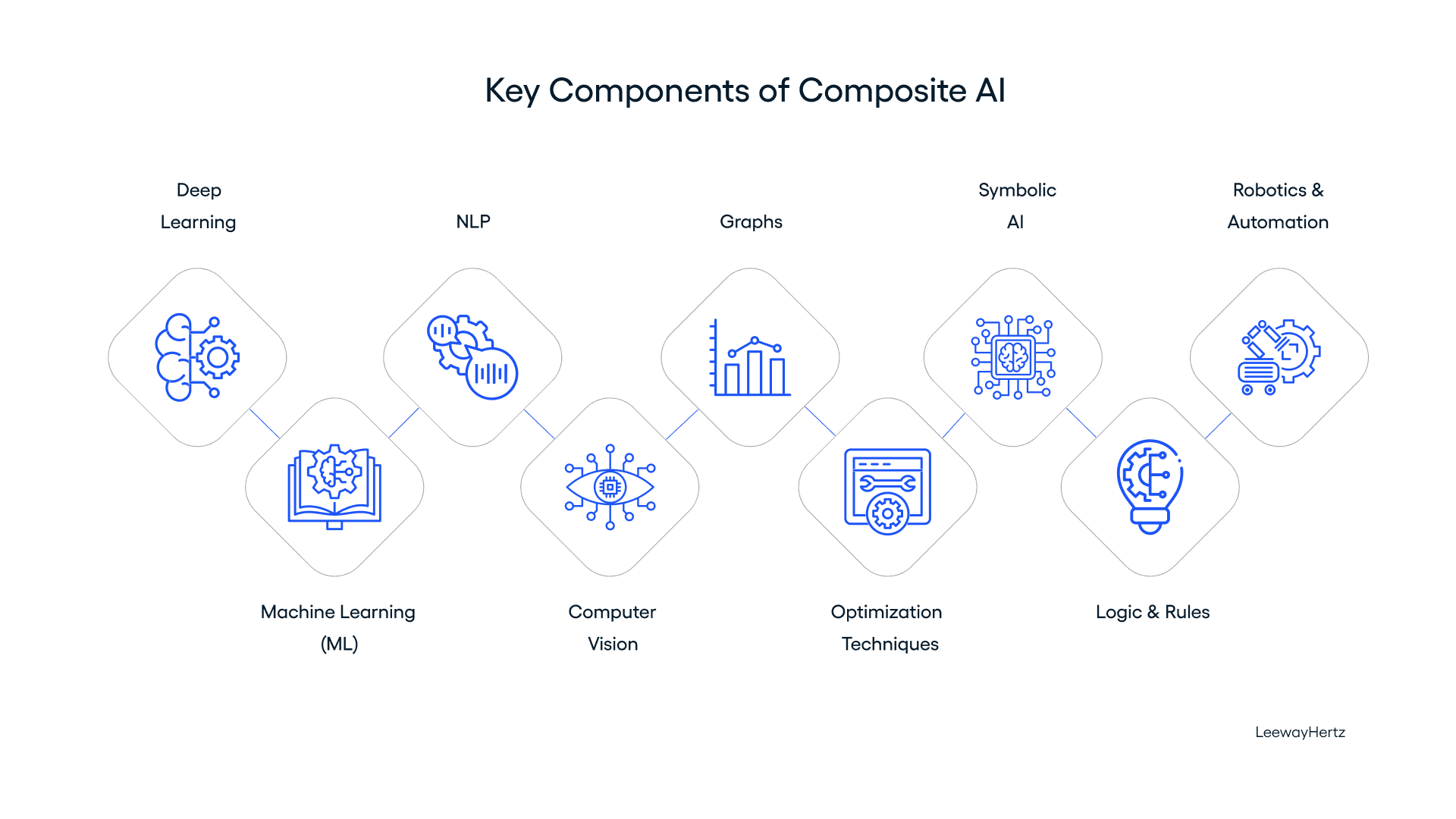
(Source: LeewayHertz’s Composite AI page)
Gartner first put composite AI on the map when it published its 2020 Hype Cycle for Emerging Technologies. Adoption has accelerated across sectors, with major technology providers and enterprises reportedly developing their own solutions.
Most notably in late 2023, Fujitsu Limited launched Fujitsu's Kozuchi AI platform. The new technology is a component of Fujitsu's Composite AI framework.
The pattern is consistent across industries: organizations that intelligently combine different AI technologies based on the specific requirements of each sub-problem outperform those using a one-size-fits-all approach.
What was impossible is now routine
Four years ago, customers told us their ideal solution didn’t exist. The math didn’t work, and no vendor—including us—could solve the problem without making major trade-offs.
The math had fundamentally changed and the results speak for themselves:
One customer expanded from 200 to 600 sites using the same resources
Another tackled previously unprofitable market segments, growing revenue by 32%
A third reduced their average setup time from three weeks to three days
Today, those same challenges aren’t just solvable—they’re routine. What once took weeks of manual setup and custom coding now happens in hours, with AI handling a substantial chunk of the complexity.
Most importantly, our customers are now saying "yes" to opportunities they previously had to turn down. Quality web data that scales is no longer a compromise. It's what we deliver every day.