
As companies recognize the value of obtaining fresh web data to fuel winning products and make better decisions, the data scraping field evolves. Now, more than ever, new tools and technologies are available to developers, making it difficult to decide how to start a new project or choose the right technology for a major migration.
The challenge is that web scraping technology is a moving target, constantly evolving alongside the web.
How can developers start their projects equipped with the most adaptable technologies and better prepare for the future of the web, considering the web will keep changing and challenge our best practices?
The answer lies in understanding the role of each technology in the evolution of data collection and then making decisions on the best combination of those technologies based on your specific needs.
Historically, web scrapers relied on endless combinations of multiple tools, each specific to a single job. We have tools for building spiders, others for proxies, and others for monitoring spiders.
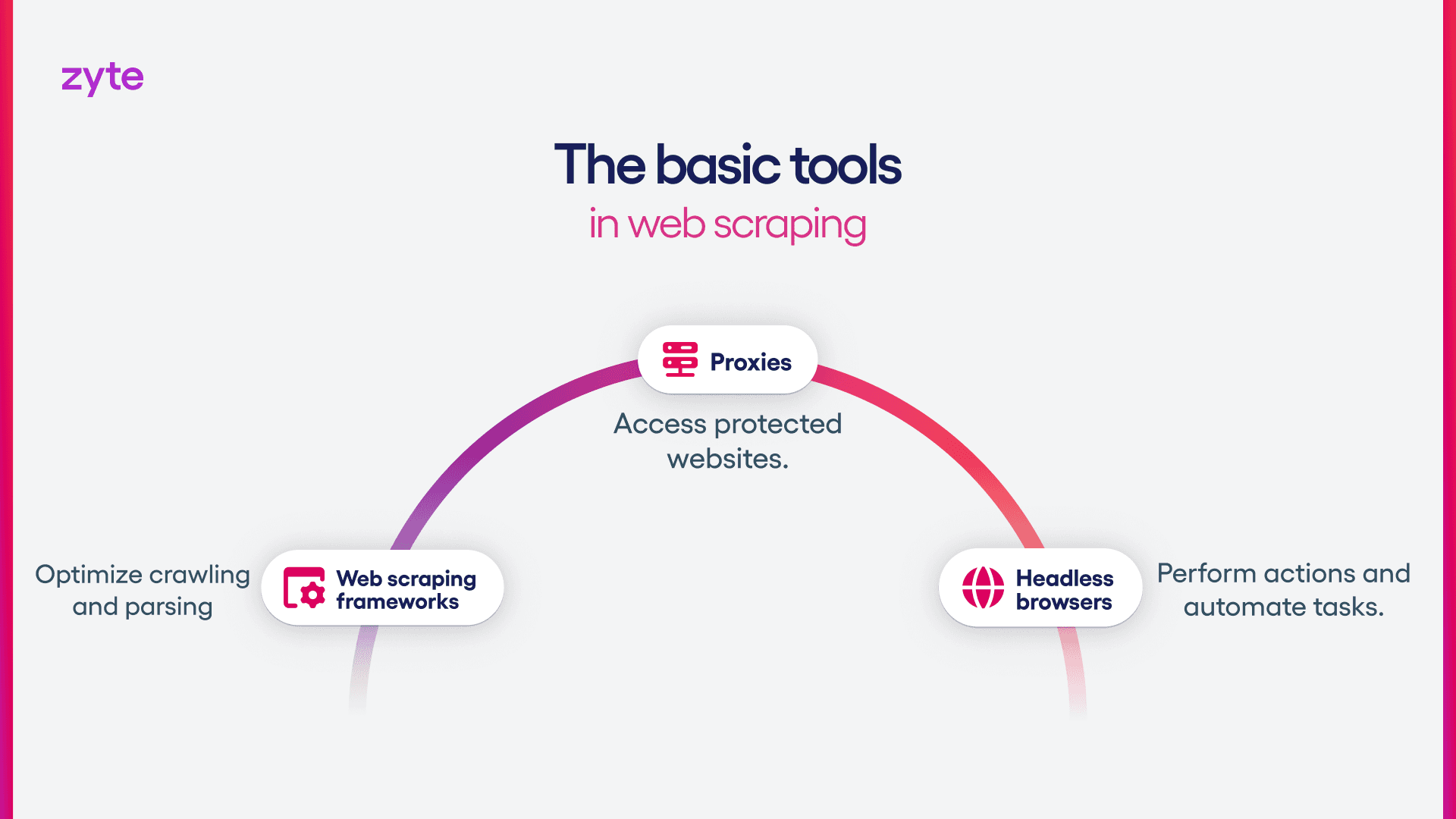
Web scraping frameworks
Software tools that perform the two main tasks in web data extraction: crawling and parsing. Easily customizable for specific needs, they usually require significant setup and configuration.
Headless browsers
Developers use headless browsers, such as Selenium, Playwright and Puppeteer, to run scripts and automate tasks without displaying a UI, as a way to quickly access content behind JavaScript or to unlock websites that require a browser. They are resource-intensive and slow tools with the advantage of minimizing bans with advanced customization.
Proxies
Proxies are used in web scraping to access websites that may be blocking traffic from bots. They vary into different categories, each with its own role in managing website bans. Simple proxies will work on basic websites, but more difficult websites will require more expensive proxies, such as residential proxies.
Identifying the right proxy type for each website is only part of the job. You also need to figure out the right combination of configurations, such as headers and user agents, which is often found through trial and error.
Simple tools for simple use cases
Development teams with sufficient bandwidth often build custom tools that include these three basic technologies. When developers can afford the time spent on customization, single-use spiders and small data scraping projects can run indefinitely on this setup.
However, there comes a point in the scaling process when more sophistication is required.
When the basics are not enough
In today’s competitive digital world, web data extraction plays a decisive role in the success of new companies and business initiatives. E-commerce companies rely on web data for dynamic and strategic price adjustments, which are crucial for long-term success.
Finance and retail companies need geographical insights from competitors and potential customers before opening new branches. News, articles, and job aggregators depend on strong, reliable data extraction systems.
Developers building web scraping systems must meet business needs—reducing costs, quickly adding data feeds, expanding data fields, and improving data quality—while facing significant challenges:
Anti-bot systems are getting stronger and more prevalent, requiring a substantial investment of time and resources in trial-and-error approaches to find the right configuration of proxies and headers for each website.
Websites frequently change their layouts due to new branding, systems, and evolving strategies, demanding regular and time-consuming spider updates.
The web relies increasingly on dynamic content, like geo-locked content or content loaded with JavaScript, requiring the deployment of browsers to simulate human behavior.
The pressure to remain competitive, combined with web scraping challenges, has made the approach of continuously integrating additional tools outdated.
The evolution of the new web scraping stack is here, and it’s necessary as we move into the future.
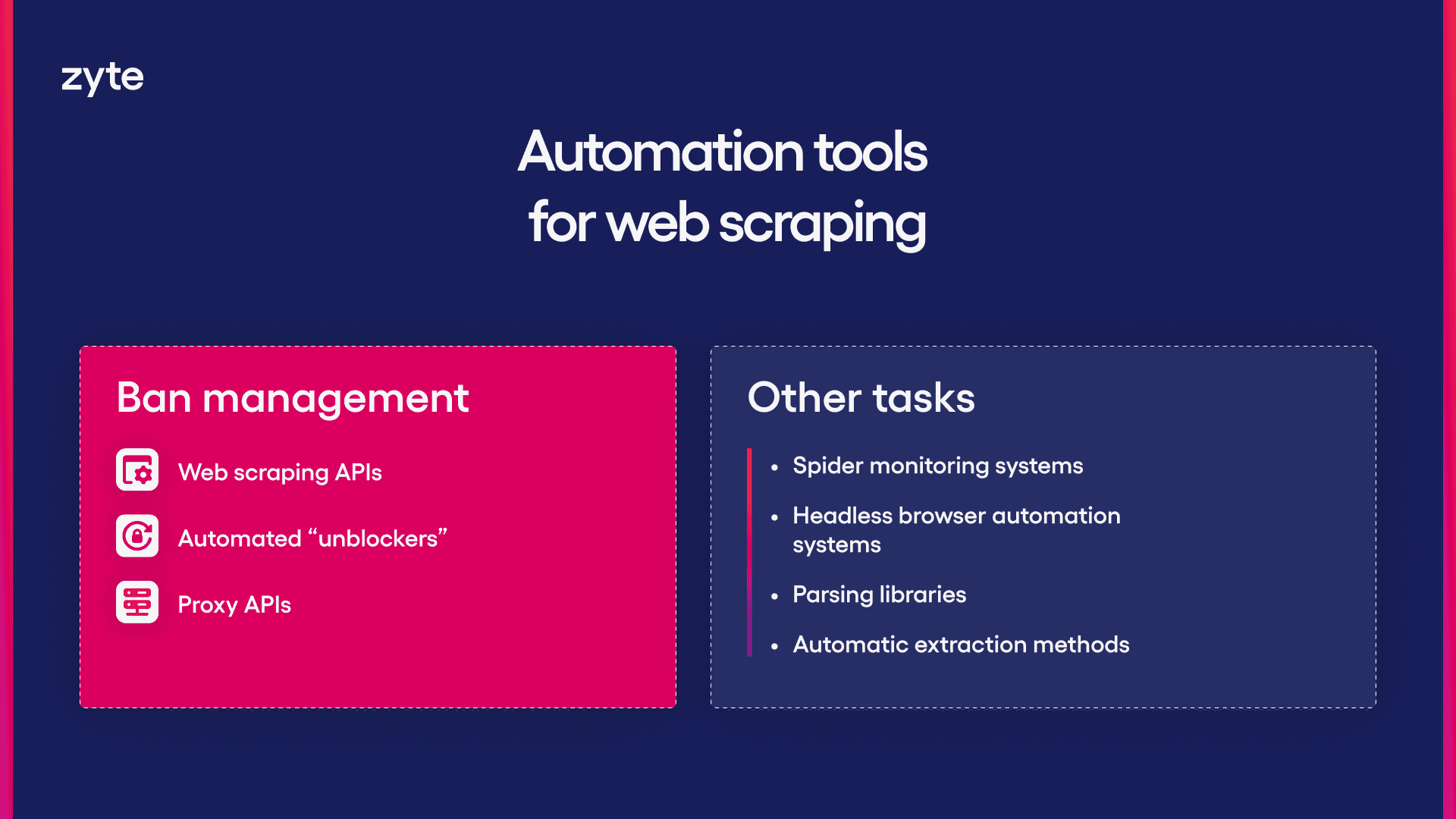
Ban management Tasks
Proxy APIs
The manual trial-and-error struggle to determine the best proxy for each website has been replaced by automated solutions such as proxy rotation tools or proxy management tools, also known as Proxy Rotation APIs or "Unblocker" APIs.
Frequently sold as premium alternatives to proxies, these tools test the right configuration of proxies and headers for each targeted website. They also perform automatic retries, proxy rotation, and rate adjustments, and are sometimes powered by AI.
Due to their higher cost, developers often rely on multiple vendors for Proxy APIs while balancing with basic proxies for easier websites. Another drawback is that they still need to be integrated with other tools in the web scraper’s toolkit, such as headless browsers.
Proxy APIs still require trial-and-error work to find the best combination of tools and configurations to keep the data flowing. However, they are capable of solving more sophisticated bans.
Automated "Unblockers"
Typically, web "unblockers" will use advanced technologies like headless browsers to access websites, whether needed or not. They are the first choice for developers and data teams lacking know-how on precise configurations for accessing sites cheaply with rotating proxies, or unwilling to invest time and money on it.
Automated "unblockers" go further than Proxy APIs, solving bans without the trial-and-error work on proxies, headless browsers and other configurations. However, that convenience has a higher fixed cost per request.
Those tools can be expensive premium solutions, even for easy websites.
Modern Web Scraping APIs
Web scraping APIs simplify and streamline the data extraction process, reducing the need for custom code. Some tools under this category can include a proxy mode or serve proxies on demand. The main advantage of using web scraping APIs over Proxy APIs is that they can deliver structured data instead of raw data, saving time in the post-processing phase.
They also incorporate several tools for web scraping, such as headless browsers, localized proxies, advanced headers configuration and more.
Other tasks
Spider Monitoring Systems
Underperforming spiders can cost businesses significantly in a world where broken spiders mean faulty data. Spider monitoring systems, like Spidermon, were created to watch all spiders and centralize their performance data for easy monitoring and decision-making.
Headless Browser Automation Systems
Single instances of headless browsers built on demand have evolved into fleets or farms, with tools that can deploy browsers with a single line of code added to the spider level.
Parsing libraries
Parsing libraries parse and extract data from HTML and XML documents, optimizing developers' time writing XPaths and regex. Scrapy and BeautifulSoup4 are good examples of this approach.
Automatic Extraction Methods
For common data types and similarly structured websites, automatic extraction methods are more efficient than writing everything by hand, especially when scalability is a concern. AI and machine learning are key components of these tools, as they can interpret HTML and translate to structured data.
There are two main ways to use artificial intelligence for automatic data extraction:
Large Language Models (LLMs) for parsing code:
LLMs write the parsing code that is hardcoded into the spiders.
When websites change, these spiders can break, requiring manual updates to the parsing code.
Machine Learning Models for data extraction:
Machine learning models are trained explicitly for data extraction routines.
These models can read websites and understand the data at runtime, adapting to changes without requiring manual updates to the spiders.
This second approach is more adaptive and resilient to website changes, making it a more robust solution for scalable web data extraction.
Balancing multiple tools can be costly and challenging
These tools have greatly increased the success rates of basic web scraping methods and continue to power large-scale data scraping operations worldwide. However, they add significant weight to developers’ setup, integration, and maintenance workloads. Additionally, the subscription fees can challenge companies' economies of scale.
This raises new questions in the market: How can developers build web scraping systems that can be started and scaled rapidly without exhausting themselves with tool integration and maintenance?
How the tooling of the future looks like
At Zyte, we believe that the future of web scraping lies in adaptive systems, such as web scraping APIs with built-in automation and AI specifically trained for data extraction.
Those systems can solve all the modern and forecasted web challenges, addressing the competitive landscape for companies in need of data, as they can easily:
Automate data extraction from multiple websites, as specifically trained AIs can understand raw HTML and translate it into reliable structured data.
Handle dynamic content and advanced anti-bot measures, adapting itself as they change and update.
Reduce the burden of tool integration and maintenance, easily connecting to multiple web scraping frameworks and other tools via the API system.

When built correctly, these systems offer high accuracy and reliability for web data, while remaining highly customizable in all aspects, including the AI-powered components.
These innovations allow developers to adopt an automation-first approach, when projects begin with the most advanced automated tools rather than using them as a last resort. AI and machine learning advancements are cutting costs and making these technologies affordable for everyone.
Conclusion
For small, initial, or experimental projects, generic tools will suffice.
However, for projects involving ten or more websites, a more robust approach with web scraping APIs will give you significant benefits.
At Zyte, we recommend starting with an automation-first approach using an AI-powered web scraping API like Zyte API. This enables your project to start getting data from the web in just a few minutes, with the option of scaling right from the start.