The 2025 Web Scraping Industry Report - For Developers
For the Developers: Scraping is Easy. Scaling (Still) Isn’t
On the surface, web scraping looks easier than ever. AI is adding intelligence at every step, but it’s also exposing gaps between getting started and getting serious.
Low-code and large language model (LLM)-powered tools promise to boost productivity, but questions remain: Will these tools replace me? How can I keep up? What’s worth investing my time in? Is it easier and cheaper to just build my own system?
Here’s what you need to know to work smart in 2025.
What Has Shifted?
1. Low-Code and LLM-Powered Tools
In the past five years or so, we see growing options of user-friendly, low-code web scraping tools geared toward non-technical users.
Tools like Portia, Parsehub, Octoparse, and Import.io were among the early entrants to the visual scraping space. However, we see many of these tools were eventually sidelined or discontinued due to strategic considerations or technical limitations in handling more complex use cases that require additional services to scale properly.
Now generative AI and agent-based frameworks have further cracked the dam, unleashing streams of semi-autonomous bots to flow through the web.
It is difficult to miss this trend when three out of the 10 trending open-source startups in Q3 2024 based on the ROSS Index are web scraping tools (ScrapegraphAI, Firecrawl, and Jina).
These emerging larger open-source tools are accompanied by smaller libraries popping up all around. Tutorials on “scraping with LLMs” have also exploded on platforms like YouTube, highlighting different GUI-based tools and natural-language-driven libraries to generate scrapers.
Earlier this year, we made Zyte’s AI scraping solution publicly available. This release wraps Zyte’s Automatic Extraction—originally launched in 2021—into Zyte API, alongside fully open-source Scrapy templates. Effectively combines extraction, ban-handling, and control into a single unified endpoint.
Other enterprise players are also moving fast: Apify released their ChatGPT plugin, OxyLabs introduced OxyCopilot, and Sequentum launched a point-and-click agent builder. Other incumbents in the space such as Scrapfly, Diffbot, and Ping Proxies expanded their offerings with low-code and LLM-powered enhancements, while newcomers like Reworkd, Kadoa, Webtap.ai, Browse.ai, and isomeric.ai were also making waves throughout last year.
2. Scraping ≠ Scaling
But it’s one thing to create a scraper; it’s another to reliably acquire web data at the scale that your business demands.
Scaling isn’t just about scraping more pages. It’s about handling challenges like maintaining data deliveries despite aggressive bans, managing a healthy pool of proxies, adapting to changes in website structures, and ensuring compliance with regulatory frameworks.
At this stage, many of these low-code or LLM-powered tools help get you from 0 to 1, not 1 to 100—where 0 to 1 is going from not having a scraper to having a scraper, while 1 to 100 is from having a scraper to having data at scale.
Cost is one often-underestimated factor that you need to consider before relying on LLM-powered tools for web scraping. It takes some iteration and experimentation to be able to use LLM in a cost efficient way to scrape and extract web data.
While it's true that LLMs will likely become cheaper over time—especially with foundation models being commoditized through market forces like the release of the free LLaMA models and other emerging alternatives like Mistral—you cannot ignore the infrastructure costs. Whether you're using cloud providers like Anthropic, Google, and OpenAI, or hosting the models yourself, the infrastructure expenses remain a significant variable to factor in.
When we did a cost benchmark between Zyte’s supervised machine learning models and OpenAI’s GPT-3.5, we discovered that extraction with the LLM-approach costs up to 50x more than Zyte’s non-LLM approach. In this webinar you can also see how Zyte’s AI stack achieves the same results as OpenAI's more recent GPT-4o model, but at a lower cost.
We discuss how Zyte approaches the cost-efficiency problem faced by LLMs under the "composite AI” point in the Industry Players section, so be sure to give it a read if you’re interested in learning more.
We will also be going into more detail about how these scraping-focused low-code tools aren’t yet addressing the operational realities of scaling in the Extract Data publication on Substack, so make sure you subscribe to get notified.
The Case for Unscalable Scraping
All that said, not everyone needs to scale. There is a legitimate place in the market for small-scale, lightweight solutions.
For example:
Interactive, headful use cases: Simple, single-user LLM “chat with a web page” tools for straightforward one-time queries on a webpage.
Small, one-time projects: Situations where a quick scrape of a single page or dataset is all that’s needed.
Ad-hoc analysis: Cases where the goal isn’t to build an ongoing pipeline but to derive insights from a specific, limited query.
For these scenarios, straightforward scraping tools offer an elegant solution.
The key takeaway: scraping and scaling serve different goals. Both have their place, but recognising the distinction is crucial to choosing the right tools.
One final cheeky point worth making is that scaling itself is actually easy. Any engineer knows that you can get to any scale with unlimited time and budget. What is difficult is scraping more pages quickly and cost effectively—which means arriving at the leanest tech and most efficient configuration.
3. Increasing Investment in Anti-bot Technology
As more bots pull, more websites push.
The Imperva Threat Research 2024 report reveals that almost 50% of internet traffic now comes from non-human sources. This number has risen from 30% in 2023.
This year’s Web Almanac—HTTP Archive’s annual state of the web report—also showed that the number of web security-related services (bot-management included) identified by Wappalyzer has nearly doubled from 36 in 2022 to 60 in 2024.
reCAPTCHA, Cloudflare, and Akamai are still sitting undisrupted in the top five, but Imperva (Distil), hCaptcha, and Sucuri are new breakouts into the top ten.
The Great Wall of Mobile
Other than desktop and mobile websites, mobile applications are also getting more difficult to extract data from.
“We observe another jump in adoption from 29% of desktop sites and 26% of mobile sites in 2022 to 33% and 32% respectively now. It seems that developers have invested in protecting more mobile websites, bringing the number of protected desktop and mobile sites closer together.” — Web Almanac 2024’s Bot protection services section.
For the past five years, we have seen more and more mobile applications employ SSL pinning, encrypt API requests and responses, and utilise code obfuscation to prevent reverse engineering and data interception. Additionally, they are increasingly adopting dynamic protocols such as WebSocket and gRPC, adding complexity to data extraction compared to traditional REST APIs. These measures align with OWASP’s Mobile Top 10 best practices for addressing Insufficient Transport Layer Protection.
Run, Mouse, Run
Another development that the Zyte web intelligence team has observed is the growing adoption of mouse movement intelligence technology.
This technology analyzes the subtle patterns and behaviors of mouse movements to differentiate between human users and automated bots. By tracking parameters such as speed, trajectory, hesitation, and pauses, mouse movement intelligence creates a behavioural fingerprint that is difficult for bots to emulate.
We also see incumbents such as Cloudflareoffering new adaptive solutions viciously titled “one-click-nuke”, and different new services are popping up this year.
Are You Human?
During a panel at Oxycon this year, the Oxylabs COO shared an anecdote that he noticed this year websites have ramped up protection to the point of harming their own users.
This issue has apparently seeped into popular culture as well.
In November, a short film was screened at The New Yorker Screening Room. The Surreal Identity Crisis of “I’m Not a Robot”, tells a story about how a series of failed Captcha tests plunges a woman into a strange new reality.
So an automated software’s “life” is not getting any easier, and apparently real web visitors also need to spend an increasing amount of time to prove—and ponder upon—their humanity.
At the end of the day, we at Zyte think this battle is a win for innovation. The Turing's Tango between anti-bot and anti-ban technologies are driving each other to become more advanced, adaptable, and robust.

A Word on Productivity in the Age of AI
“AI won’t replace you; people using AI will.”
By now, you’ve heard this so often it probably reads like a desktop wallpaper. But let’s face it—it’s a clever play on semantics that does little to soothe our existential dread. Deep down, most of us aren’t imagining Artificial General Intelligence (AGI) overlords swooping in to take over our jobs (wouldn’t that be nice?).
What we’re really asking is: Is my livelihoods safe? What do I need to do to keep up? And perhaps even more crucially: What is my employer planning to do with my job in the age of AI?
Those are questions beyond the scope of this article, but to even begin to answer that, we need to consider the two things that are infinite in the world of business: human imagination and ambition.
Yes, AI promises automation of knowledge work, but the game isn’t always zero-sum. Jevon’s Paradox applies here. Improvements in labor efficiency tend to increase its demand, not decrease it as you might expect. Andrew Ng recently highlighted the importance of data engineering is rising. As data extraction becomes easier, faster, and cheaper, the demand and expectations for different types of data increases. As AI tools lower the barrier to entry, new data opportunities emerge. This means you won’t likely run out of things to build and optimize.
The tools may change, but the demand for skilled software engineers won’t. Your edge lies in knowing how to wield these tools while staying ahead of the curve.
So, which tools should you skip for the thrill of tinkering, and which are worth using to handle the boring bits?
The Rise of APIs in Web Scraping
It’s almost instinctual now to think API-first when dealing with the interoperability of web services. How else are you supposed to build?
But let’s rewind a bit—APIs weren’t always the elegant go-to solution. In fact, ask any developer from the early 2000s about SOAP, and you’ll see them wince in PTSD.
Thankfully, things started shifting when REST gained traction. By the late 2000s, RESTful APIs became the lingua franca of the web, thanks in no small part to social media platforms which opened up their APIs for developers to build on.
Fast forward to the mid-2010s, and we see the emergence of modern API marketplaces. Apigee and RapidAPI, for instance, picked up where early players like ProgrammableWeb and Mashape left off. Around the same time, the rise of webhooks—popularised by Zapier’s success—combined with the emergence of microservices and serverless architecture, firmly established the API-first mindset.
Today, APIs aren’t just the standard way to think about integrating and scaling services blocks—they’re business models. It is so common for companies now to offer APIs as standalone products.
There are generally four types of APIs that help you access web data at scale:
Proxy APIs
Unblocker APIs
Infrastructure APIs (headless and serverless). E..g. Browserstack, Browserless, AWS Lambda, and Google Cloud Functions
Crawling and parsing APIs for specific websites or types of websites—sometimes with AI-powered extraction. E.g. SERP APIs, e-commerce spiders, and AI scraping APIs
It makes sense. APIs are necessary abstractions. Once you have built the crawlers with your scraping framework of choice and hosted them, you just delegate the various tasks to dedicated interfaces, streamlining the process.
Some of you opted to use and orchestrate each type for specific tasks, some chose a full-stack web scraping API like Zyte API that wraps all these components and functionalities under one endpoint.
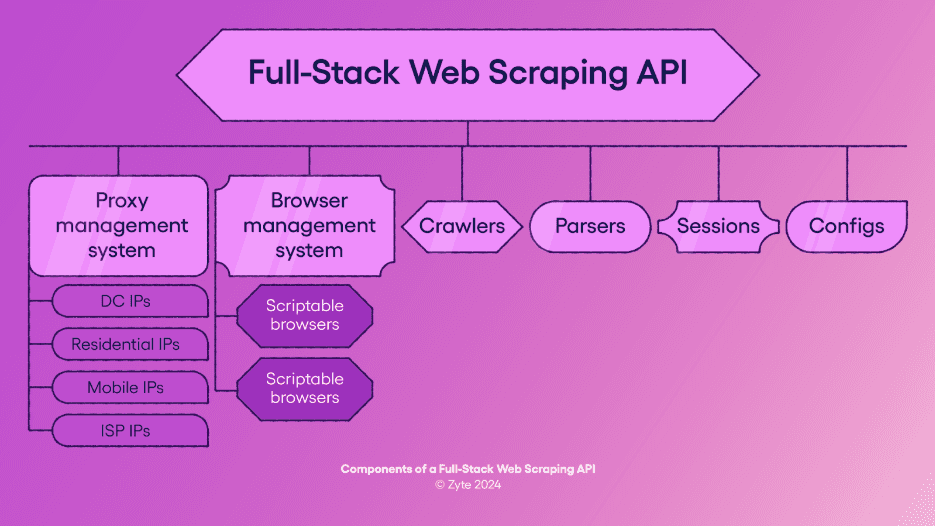
Each approach has its pros and cons:
Orchestrating multiple APIs allows for more flexibility, as you can fine-tune each part of the process to your specific needs.
Pros: Fine-grained control over each component; ability to optimise for individual tasks.
Cons: Increased complexity in managing and integrating multiple services; higher overhead in terms of setup and maintenance.
Using a universal API offers a more streamlined approach, simplifying your architecture by providing a one-stop solution for multiple tasks.
Pros: Simplified technical integration and improved visibility into the total cost of ownership through a single pricing model that eliminates the need to manage multiple services or contracts.
Cons: Potential limitations in customisation; reliance on a single vendor for all functionalities.
Choosing the right approach depends on your specific needs—whether you value control and flexibility or simplicity and efficiency.
We have to acknowledge that scaling a web data extraction project is often still a convoluted (yet intellectually satisfying) experience for many software engineers. This process involves reverse engineering, experimenting with different session management techniques, and juggling intricate infrastructure. Action and control feel good. This is one reason why many developers still prefer to orchestrate their own scraping symphony and resist “automagical” tools that could take over the tedious aspects of their work.
What to Watch Out For
Customizing low-code tools requires work. Reliance on generic tools that lack depth in edge-case handling or site-specific nuances.
Growing complexity: Coordinating distributed systems, retry logic, and maintaining compliance across jurisdictions can overwhelm teams without dedicated resources.
Misplaced expectations: Non-technical teams might overestimate what low-code solutions can achieve. Developers must manage expectations, communicate limitations, and advocate for the right tools for the job.
Learning stagnation: Developers relying solely on these tools risk missing out on foundational scraping and scaling skills. You are welcome to join our Extract Data developer community of over 10,000 web scraping enthusiasts on Discord to keep up with the latest in the space.
Ethical considerations: Scraping sensitive or grey-area data without clear consent can harm your reputation or lead to enforcement actions.
Things to Remember
Think beyond the binary. One common misconception in web scraping is that the more expensive solution is, the better. Typically, you're faced with two options: A) premium, feature-rich tools built for complex tasks but far too costly for everyday scraping, and B) a set of budget-friendly tools tailored for simpler scraping tasks. But remember that there are tools out there like Zyte API that C) break this rigid binary by offering a dynamic solution that applies the right technologies to the complexity of the site. Instead of overpaying for unnecessary capabilities or settling for underpowered tools, you simply pay less for simple sites and pay more for complex sites—all through one interface. This simplifies the overall activity by being usable for sites of all levels, saving you time and attention to constantly make the decisions yourself.
Keep your goal in mind. Low-code and LLM-powered tools shine in the early stages, but translating a proof-of-concept into a scalable, reliable system requires robust infrastructure and evolving configurations.
Plan for workflows. Master the integration of low-code tools into your workflows, while retaining your ability to solve edge-case problems manually.
Evaluate ROI. Scraping projects can be expensive at scale. Continuously evaluate whether the value of the data collected justifies the maintenance cost. This includes the intangible cost of decision making.