The 2025 Web Scraping Industry Report: Surviving the Shifts
What Developers, Business Leaders, and Industry Players Need to Know to Thrive
Introduction
It’s never been easier to start extracting data from the web. Our awareness and appetite for data have also never been greater. The AI boom has unleashed a firehose of natural language-enabled libraries, crawling tools, and parsing technologies, dramatically lowering the barrier to entry for web scraping to a wider range of users.
This democratization of tools and expertise drives down the cost of web data acquisition. Buying and getting web data is getting cheaper and easier—a benefit data buyers are now enjoying.
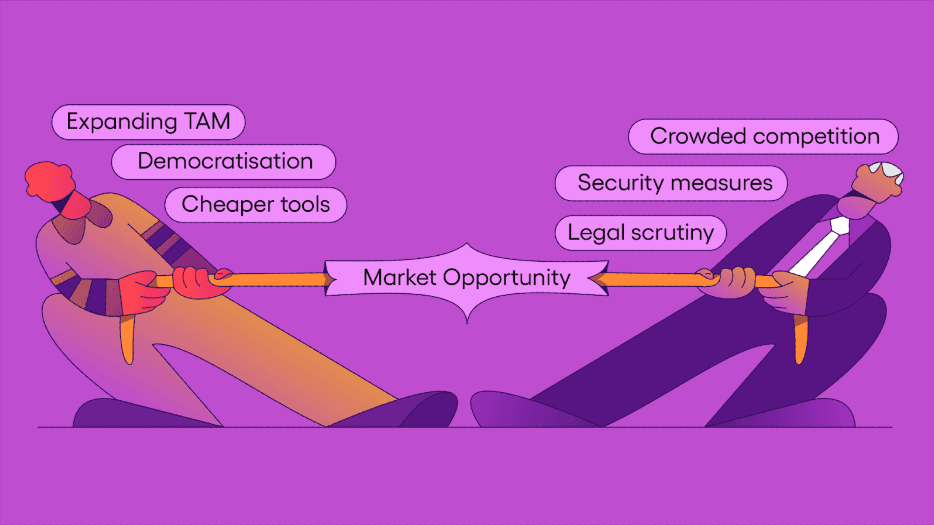
As a result, the total addressable market for web data extraction has massively grown and the web scraping space has become increasingly crowded. New players join a long-list of established names trying to get a slice of the pie and hustling to strategically position their intelligence-infused products in this bustling market.
Meanwhile, the number of companies offering web security technologies have doubled in the past two years, reflecting the growing demand as more websites ramp up their defenses against malicious bots engaging in unethical activities. This has added pressure for legitimate web scraping use cases for public data which often get unfairly caught up in these efforts.
Adding to this complexity is the growing scrutiny around the legality of web scraping. The rise of generative AI models trained on web data has brought issues of copyright and data ownership into mainstream focus. These tensions have sparked high-profile lawsuits and high-pressure tactics by big tech companies trying to build business moats on top of their user-generated content platforms.
In a nutshell, those are the market forces propelling the industry into 2025—the same dynamics, moving at an unprecedented pace.
Whether you’re managing a suite of web data extraction products, leading business strategies around web data utilization, or wrangling the data extraction code yourself, it can feel like an overwhelming torrent of developments vying for your attention.
In this report, we will highlight the ones that deserve your attention, and delve into each from an angle that is relevant to you.
Here is how we will break it down:
For developers, we'll explore how web scraping is becoming more accessible than ever, even as they tackle the growing challenges of scaling with web scraping APIs.
For industry players, we’ll navigate the two main driving forces shaping the landscape: the opportunity that AI has unlocked, and the challenge of achieving and maintaining compliance.
For business leaders, we’ll dive into how the economics of buying data is catching up to building in-house solutions and how you can make the most out of it to benefit your data strategy.
For each, we’ll go through:
The key shifts and what they mean for you
Risks to watch out for
Tips and recommendations
Here at Zyte we have observed and contributed to the evolution of the web scraping ecosystem since 2010. We don’t pretend to have all the answers, but we can share what we see and what worked for us.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
